Expressive Speech Synthesis with Tacotron
Table of Contents
At Google, we’re excited about the recent rapid progress of neural network-based text-to-speech (TTS) research. In particular, end-to-end architectures, such as the Tacotron systems we announced last year, can both simplify voice building pipelines and produce natural-sounding speech. This will help us build better human-computer interfaces, like conversational assistants, audiobook narration, news readers, or voice design software.
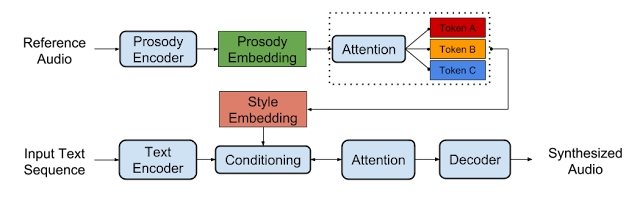
To deliver a truly human-like voice, however, a TTS system must learn to model prosody, the collection of expressive factors of speech, such as intonation, stress, and rhythm. Most current end-to-end systems, including Tacotron, don’t explicitly model prosody, meaning they can’t control exactly how the generated speech should sound. This may lead to monotonous-sounding speech, even when models are trained on very expressive datasets like audiobooks, which often contain character voices with significant variation.
Today, we are excited to share two new papers that address these problems.
Source: googleblog.com