Looking to Listen: Audio-Visual Speech Separation
Table of Contents
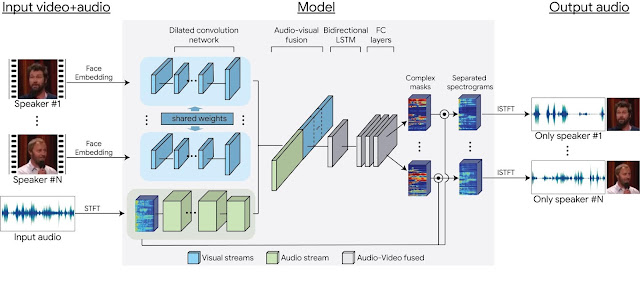
People are remarkably good at focusing their attention on a particular person in a noisy environment, mentally “muting” all other voices and sounds. Known as the cocktail party effect, this capability comes natural to us humans. However, automatic speech separation — separating an audio signal into its individual speech sources — while a well-studied problem, remains a significant challenge for computers.
Source: googleblog.com


