Deep Learning Research: Creating Adaptable Meta-Learning Models
Table of Contents
Adaptability is one of the key cognitive abilities that defined us as humans. Even as babies, we can intuitively shift between similar tasks even if we don’t have prior training on them. This contrasts with the traditional train-and-test approach of most artificial intelligence(AI) systems which require an agent to go through massive amounts of training before it can master a specific task.
By definition, train-and-test systems are not very adaptable and, consequently, they are not very applicable to scenarios that operate in real word environments. Improving the adaptability of AI systems has been one of the core areas of research of an increasingly popular discipline known as meta-learning that focuses on improving the learning abilities of AI agents. In neuroscience literature, cognitive flexibility or adaptability is commonly ascribed to prefrontal cortex (PFC) and working memory in the brain.
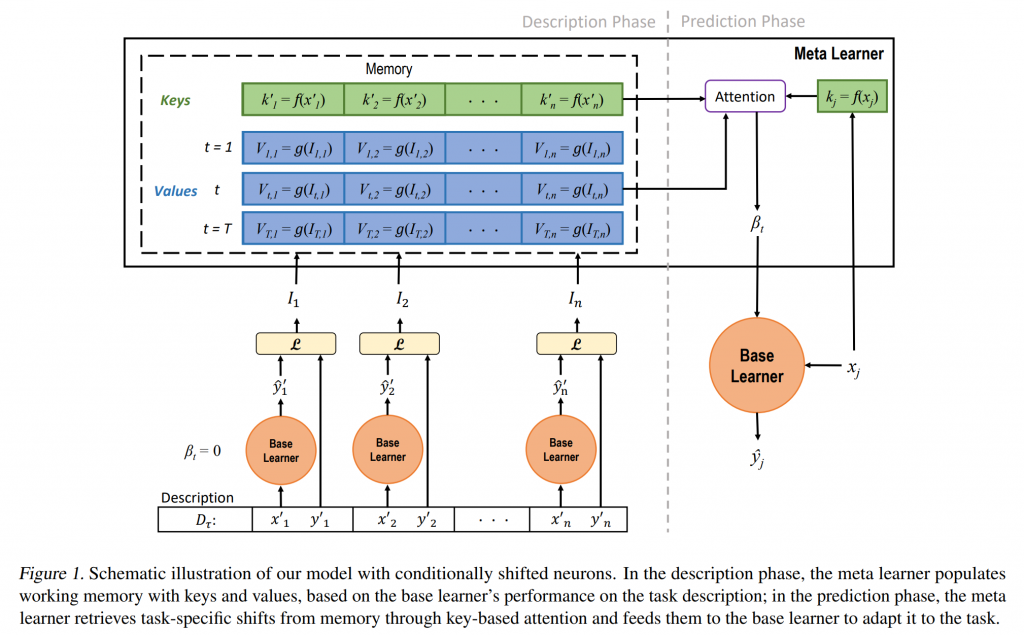
Neuroscientific evidence suggests that these areas use incoming information to support task-specific temporal adaptation and planning. Recently, researchers from the Microsoft AI lab in Montreal published a research paper that mimics some of these neuroscientific principles in a new technique known as cognitive shifted neurons(CSN).
Source: towardsdatascience.com