Peloton: Uber’s Unified Resource Scheduler for Diverse Cluster Workloads
Table of Contents
Cluster management, a common software infrastructure among technology companies, aggregates compute resources from a collection of physical hosts into a shared resource pool, amplifying compute power and allowing for the flexible use of data center hardware. At Uber, cluster management provides an abstraction layer for various workloads. With the increasing scale of our business, the efficient use of cluster resources becomes very important.
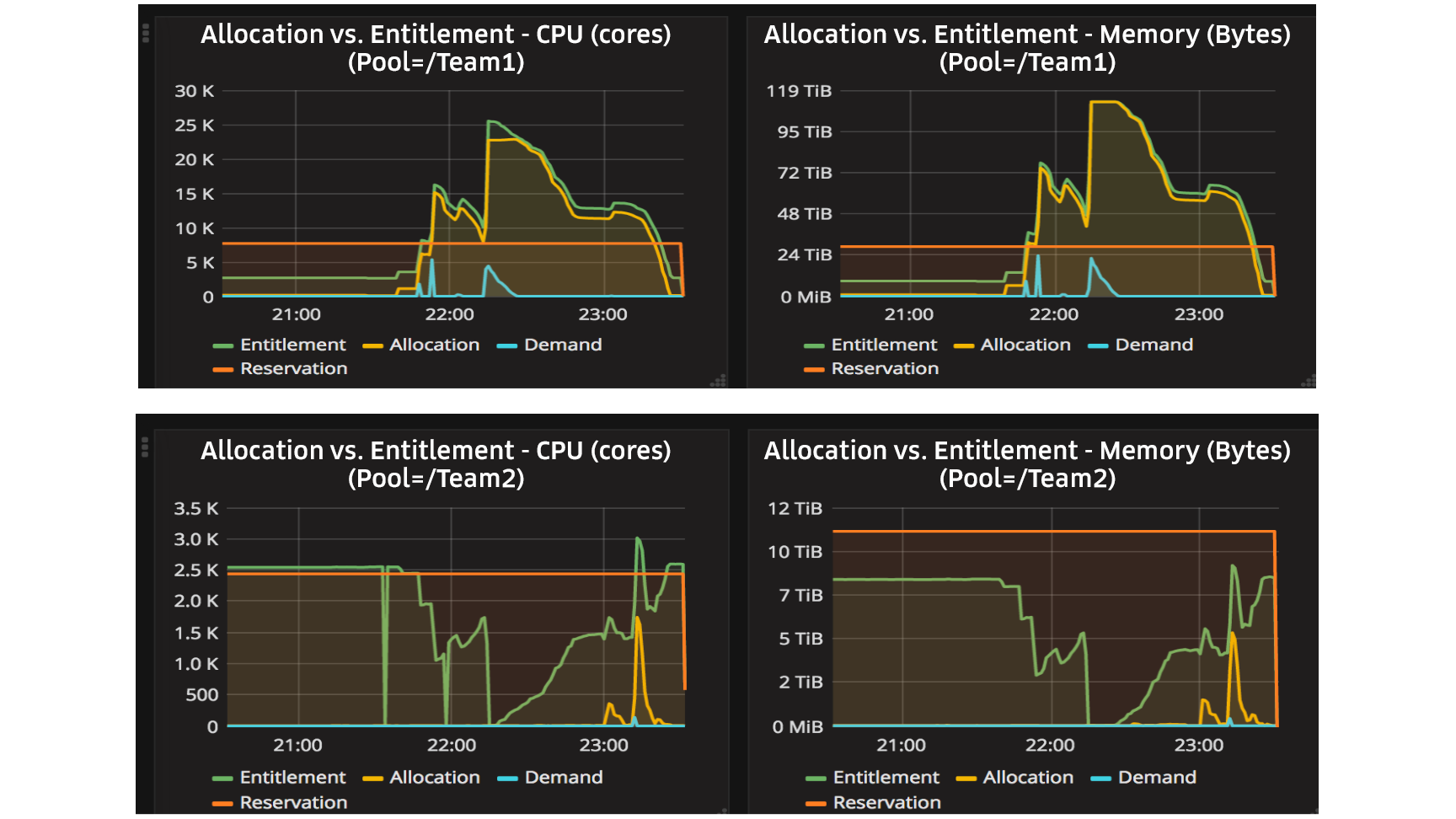
However, our compute stack was underutilized due to several dedicated clusters for batch, stateless, and stateful use cases. In addition, the very dynamic nature of our business means vast fluctuations in rideshare demand due to holidays and other events. These edge cases have led us to over-provision hardware for each cluster in order to handle peak workloads.
Relying on dedicated clusters also means that we can’t share compute resources between them. During peak periods, one cluster may be starving for resources while others have resources to spare. To make better use of our resources, we needed to co-locate these workloads on to one single compute platform.
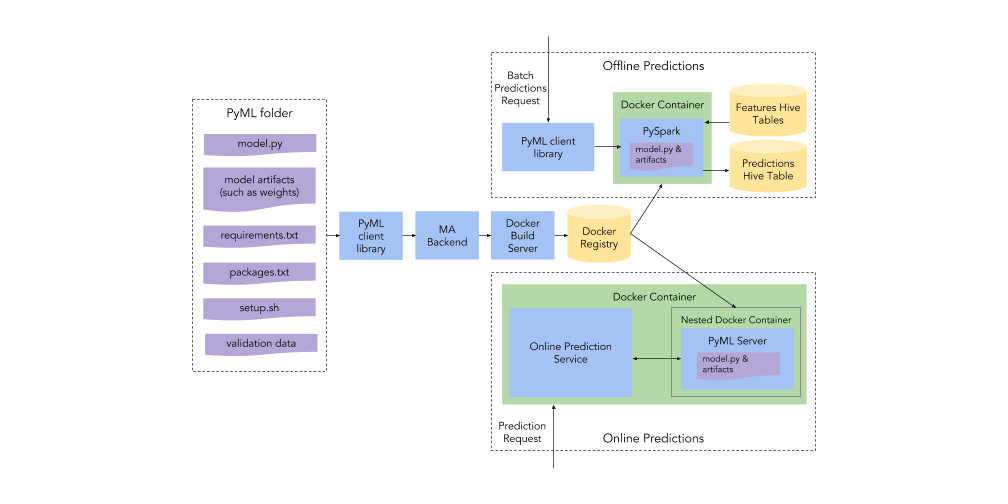
The resulting efficiencies would reduce the technical cost per trip on our infrastructure, ultimately benefiting our driver-partners and riders who depend on Uber to make a living or get around. The solution we arrived at was Peloton, a unified scheduler designed to manage resources across distinct workloads, combining our separate clusters into a unified one. Peloton supports all of Uber’s workloads with a single shared platform, balancing resource use, elastically sharing resources, and helping us plan for future capacity needs.
Source: uber.com