Cross shard transactions at 10 million requests per second
Table of Contents
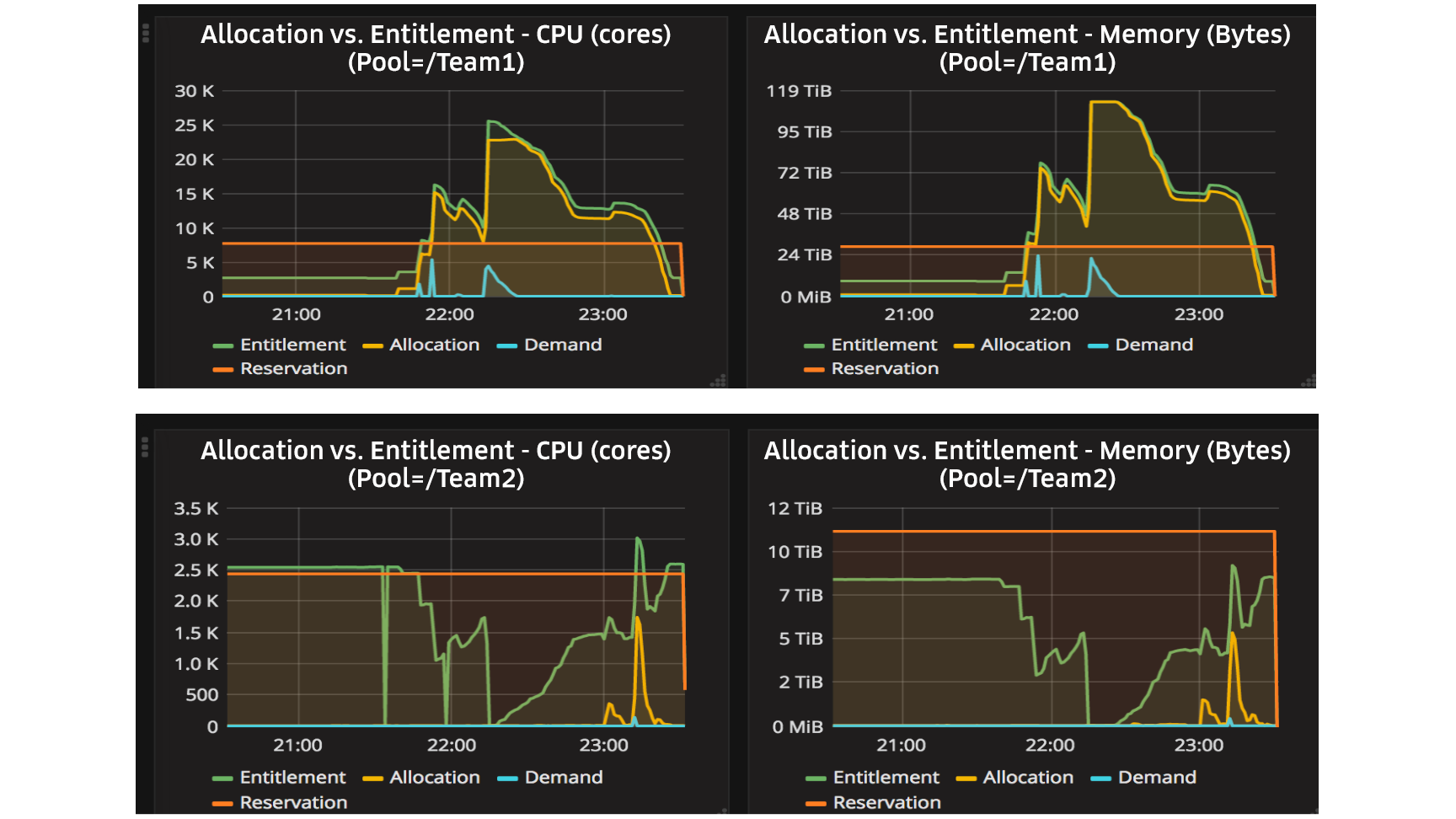
Dropbox stores petabytes of metadata to support user-facing features and to power our production infrastructure. The primary system we use to store this metadata is named Edgestore and is described in a previous blog post, (Re)Introducing Edgestore. In simple terms, Edgestore is a service and abstraction over thousands of MySQL nodes that provides users with strongly consistent, transactional reads and writes at low latency.
Edgestore hides details of physical sharding from the application layer to allow developers to scale out their metadata storage needs without thinking about complexities of data placement and distribution. Central to building a distributed database on top of individual MySQL shards in Edgestore is the ability to collocate related data items together on the same shard. Developers express logical collocation of data via the concept of a colo, indicating that two pieces of data are typically accessed together.
In turn, Edgestore provides low-latency, transactional guarantees for reads and writes within a given colo (by placing them on the same physical MySQL shard), but only best-effort support across colos. While the product use-cases at Dropbox are usually a good fit for collocation, over time we found that certain ones just aren’t easily partitionable. As a simple example, an association between a user and the content they share with another user is unlikely to be collocated, since the users likely live on different shards.
Even if we were to attempt to reorganize physical storage such that related colos land on the same physical shards, we would never get a perfect cut of data.
Source: dropbox.com