Scaling Spark Streaming for Logging Event Ingestion
Table of Contents
Walking over a stream during an Airbnb Experience in Kuala Lumpur. Searching, viewing, and booking such Experiences will all produce logging events that will be processed by our stream processing framework. Logging events are emitted from clients (such as mobile apps and web browser) and online services with key information and context about the actions or operations.
Each event carries a specific piece of information. For example, when a guest searches for a beach house in Malibu on Airbnb.com, a search event containing the location, checkin and checkout dates, etc. would be generated (and anonymized for privacy protection). At Airbnb, event logging is crucial for us to understand guests and hosts and then provide them with a better experience.
It informs decision-making in business and drives product development in engineering functions such as Search, Experimentation, Payments, etc. As an example, logging events are a major source for training machine learning models for search ranking of listings. Logging events are ingested into the data warehouse in near real-time and serve as a source for many ETL and analytics jobs.
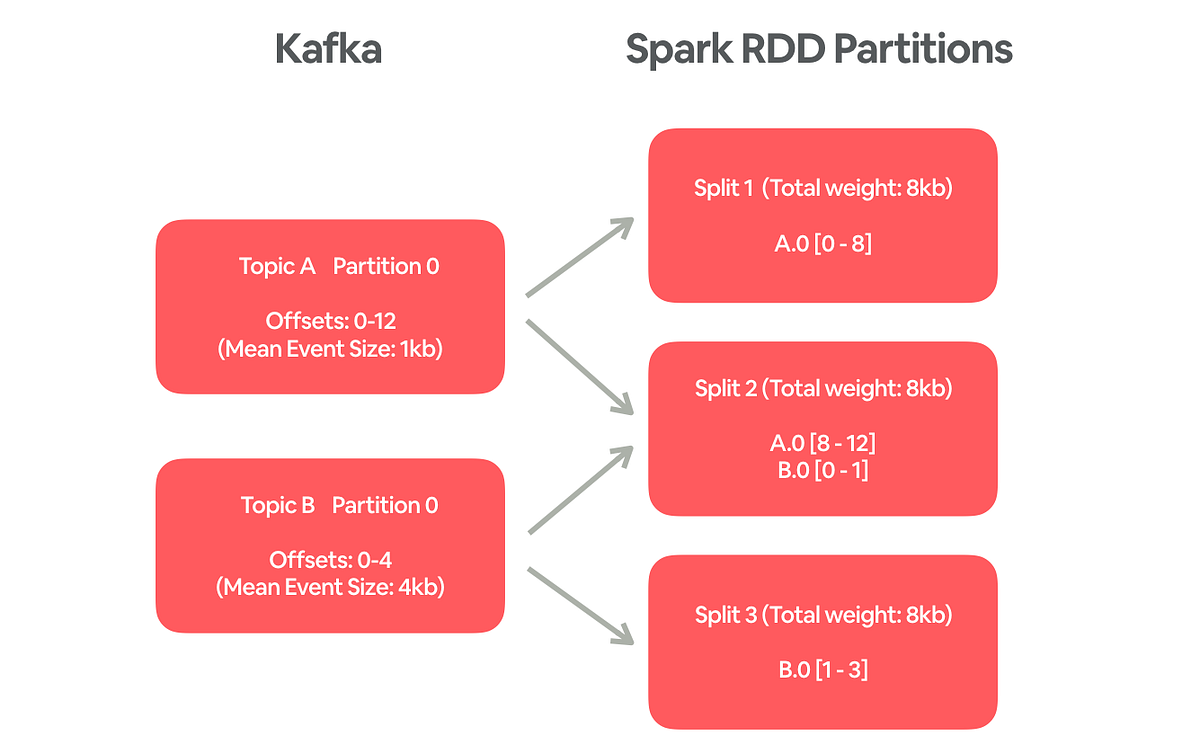
Events are published to Kafka from clients and services. A Spark streaming job (built on top of Airstream, Airbnb’s streaming processing framework) continuously reads from Kafka and writes the events to HBase for deduplication. Finally, events are dumped from HBase into a Hive table hourly.
Since the logging events are input to many pipelines and power numerous dashboards across the entire company, it is utterly important to make sure they land in the data warehouse in a timely fashion and meet the SLAs.
Source: medium.com