Observability at Scale: Building Uber’s Alerting Ecosystem
Table of Contents
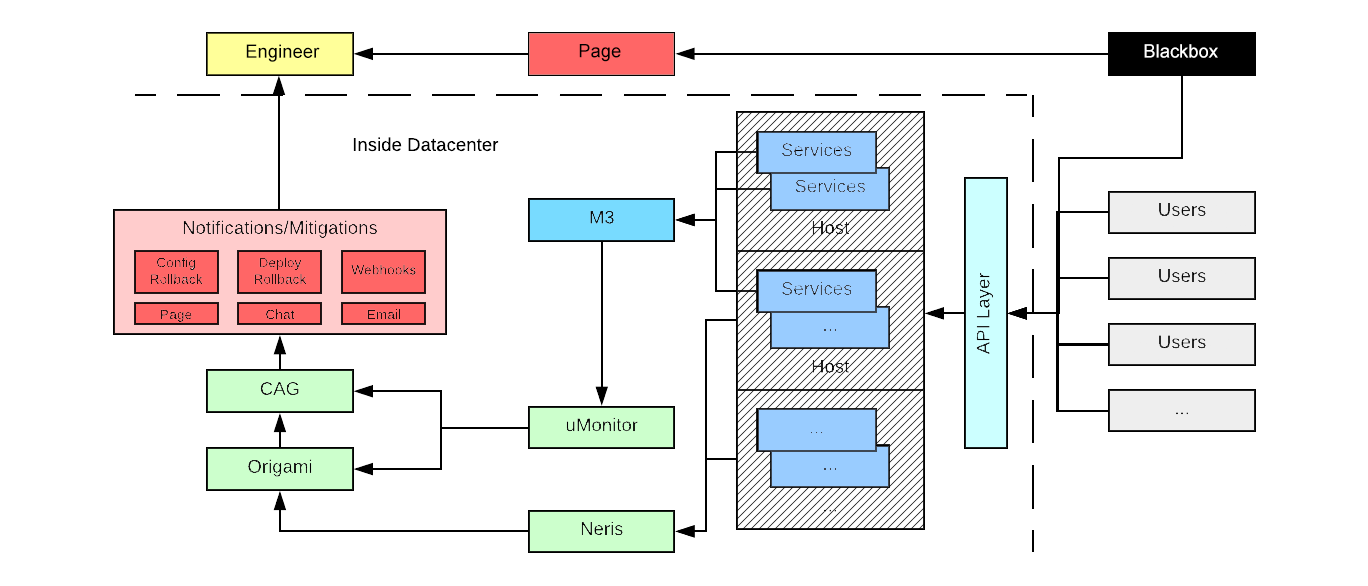
Uber’s software architectures consists of thousands of microservices that empower teams to iterate quickly and support our company’s global growth. These microservices support a variety of solutions, such as mobile applications, internal and infrastructure services, and products along with complex configurations that affect these products at city and sub-city levels. To maintain our growth and architecture, Uber’s Observability team built a robust, scalable metrics and alerting pipeline responsible for detecting, mitigating, and notifying engineers of issues with their services as soon as they occur.
Specifically, we built two in-data center alerting systems, called uMonitor and Neris, that flow into the same notification and alerting pipeline. uMonitor is our metrics-based alerting system that runs checks against our metrics database M3, while Neris primarily looks for alerts in host-level infrastructure. Both Neris and uMonitor leverage a common pipeline for sending notifications and deduplication.
We will dive into these systems, along with a discussion on our push towards more mitigation actions, our new alert deduplication platform called Origami, and the challenges in creating alerts with high signal-to-noise ratio. In addition, we also developed a black box alerting system which detects high level outages from outside the data center in cases where our internal systems fail or we have full data center outages. A future blog article will talk about this setup.
Source: uber.com