Predictive Scaling for EC2, Powered by Machine Learning
Table of Contents
When I look back on the history of AWS and think about the launches that truly signify the fundamentally dynamic, on-demand nature of the cloud, two stand out in my memory: the launch of Amazon EC2 in 2006 and the concurrent launch of CloudWatch Metrics, Auto Scaling, and Elastic Load Balancing in 2009. The first launch provided access to compute power; the second made it possible to use that access to rapidly respond to changes in demand. We have added a multitude of features to all of these services since then, but as far as I am concerned they are still central and fundamental!
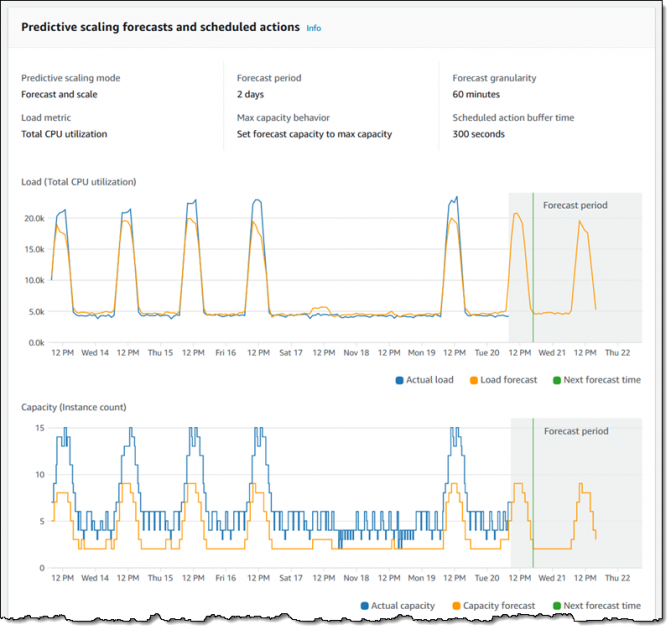
New Predictive Scaling Today we are making Auto Scaling even more powerful with the addition of predictive scaling. Using data collected from your actual EC2 usage and further informed by billions of data points drawn from our own observations, we use well-trained Machine Learning models to predict your expected traffic (and EC2 usage) including daily and weekly patterns. The model needs at least one day’s of historical data to start making predictions; it is re-evaluated every 24 hours to create a forecast for the next 48 hours.
Source: amazon.com


