Montezuma’s Revenge Solved by Go-Explore, a New Algorithm for Hard-exploration Problems
Table of Contents
In deep reinforcement learning (RL), solving the Atari games Montezuma’s Revenge and Pitfall has been a grand challenge. These games represent a broad class of challenging, real-world problems called “hard-exploration problems,” where an agent has to learn complex tasks with very infrequent or deceptive feedback. The state-of-the-art algorithm on Montezuma’s Revenge gets an average score of 11,347, a max score of 17,500, and solved the first level at one point in one of ten tries.
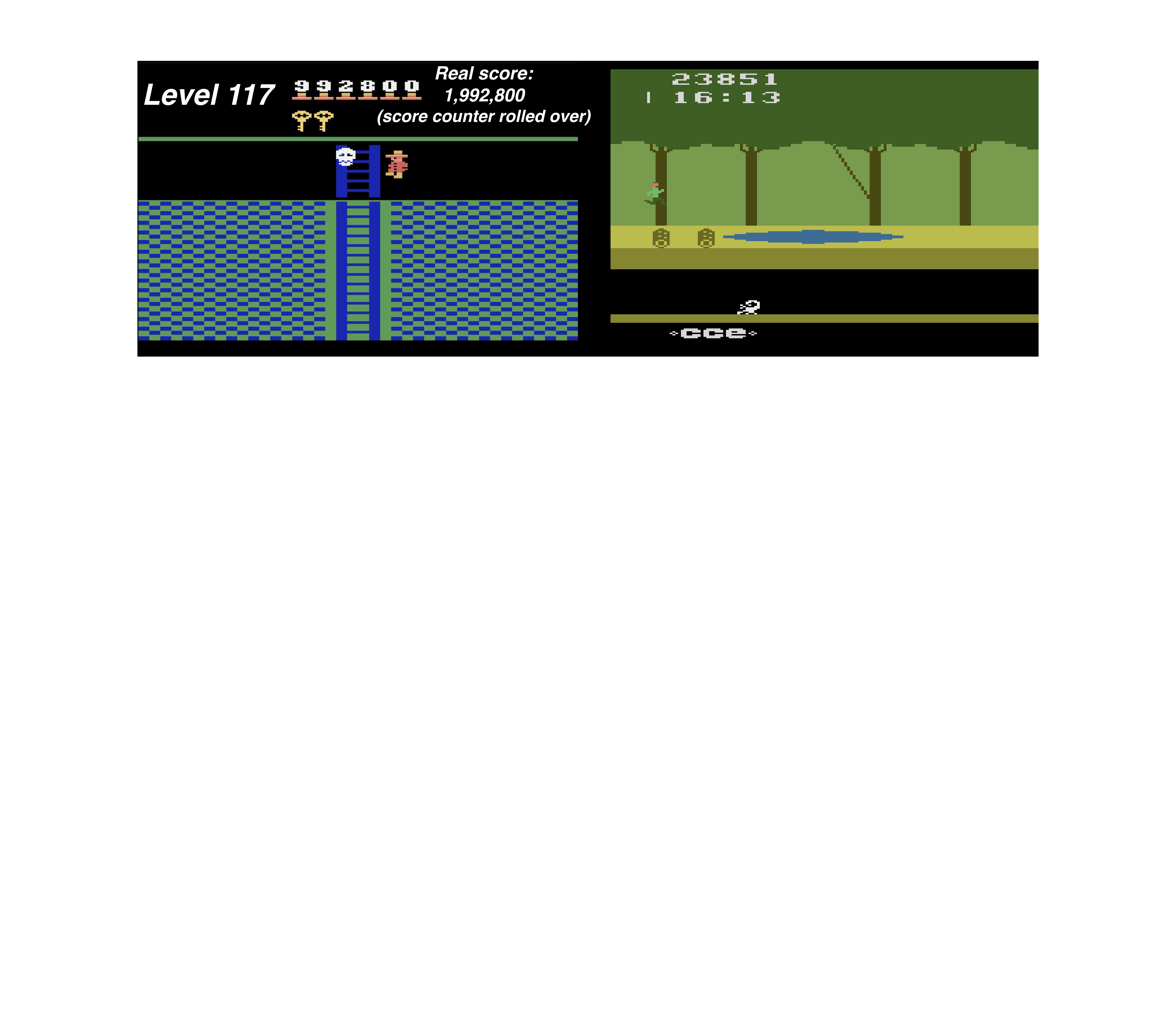
Surprisingly, despite considerable research effort, so far no algorithm has obtained a score greater than 0 on Pitfall. Today we introduce Go-Explore, a new family of algorithms capable of achieving scores over 2,000,000 on Montezuma’s Revenge and scoring over 400,000 on average! Go-Explore reliably solves the entire game, meaning all three unique levels, and then generalizes to the nearly-identical subsequent levels (which only differ in the timing of events and the score on the screen).
We have even seen it reach level 159!
Source: uber.com