Implementing the Netflix Media Database
Table of Contents
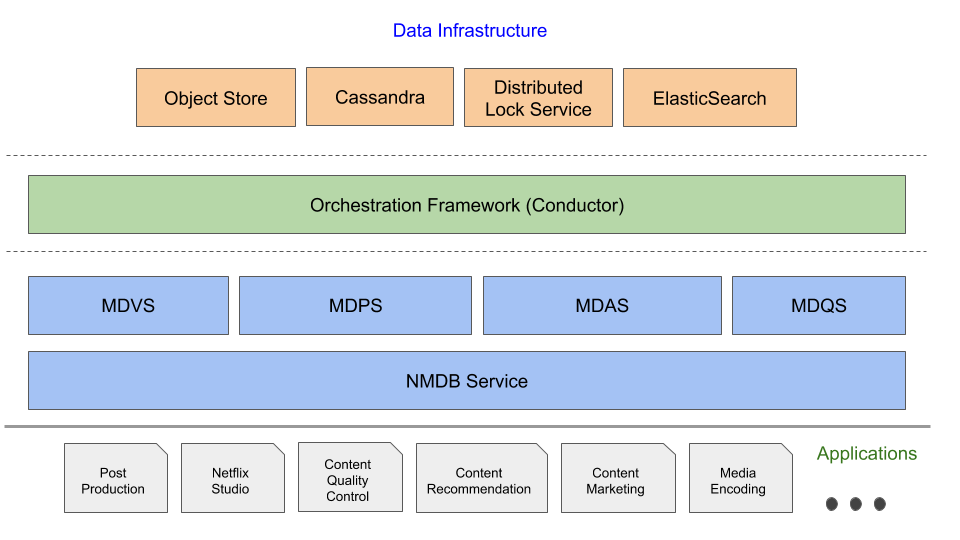
In the previous blog posts in this series, we introduced the Netflix Media DataBase (NMDB) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements—these will serve as the necessary motivation for the architectural choices we made. A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve.
NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries. At any given time there could be several applications that are trying to persist data about a media asset (e.g., image, video, audio, subtitles) and/or trying to harness that data to solve a business problem. Some of the essential elements of such a data system are (a) reliability and availability—under varying load conditions as well as a wide variety of access patterns; (b) scalability—persisting and serving large volumes of media metadata and scaling in the face of bursty requests to serve critical backend systems like media encoding, (c) extensibility—supporting a demanding list of features with a growing list of Netflix business use cases, and (d) consistency—data access semantics that guarantee repeatable data read behavior for client applications.
The following section enumerates the key traits of NMDB and how the design aims to address them.
Source: medium.com


