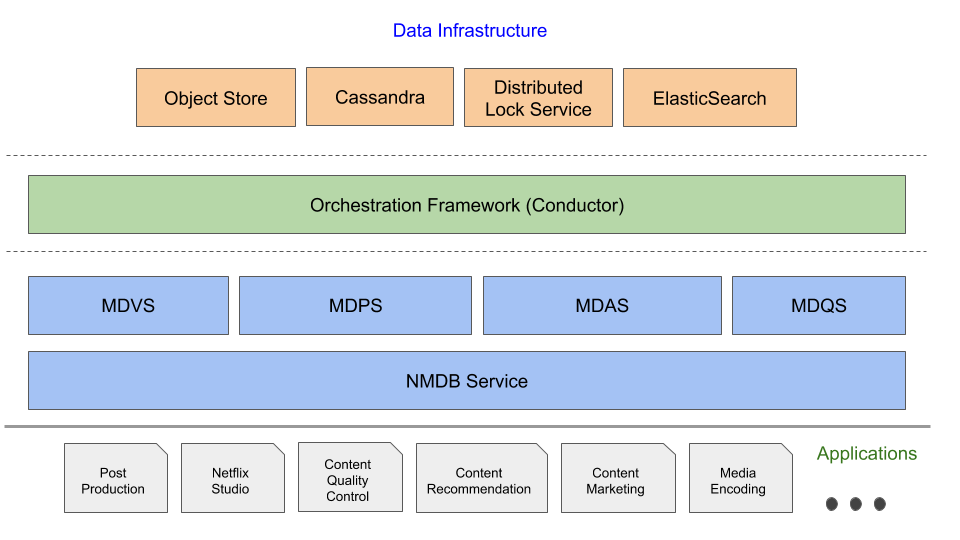
Cape Technical Deep Dive
Table of Contents
In this post, we’ll take a deep dive into the design of the Cape framework. First, we’ll discuss Cape’s architecture. Then we’ll look at the core scheduling component of the system.
Throughout, we’ll focus the discussion on a few key design decisions. Before we begin, let’s touch on a few of our principles for developing and maintaining Cape. These principles were proposed based on learnings from the development of other systems at Dropbox, especially from Cape’s predecessor Livefill.
These principles were critical for both the project’s success and the ongoing maintenance of the system. Modularization From the beginning we explicitly took a modular approach to system design; this is critical for isolating complexities. We created modules with clearly defined functionalities, and carefully designed the communication protocols between these modules.
This way, when building a module we only needed to worry about a limited number of issues. Testing was easy since we could verify each module independently. We also want to highlight the importance of keeping module interface to a minimum.
It’s easier to reason about interaction between the modules when their interfaces are small. What’s more, a small interface is more easily adapted to new use cases. Clear boundaries between system logic and application-specific logic In Cape it’s common for a component to contain procedures for both system logic and application-specific logic.
For instance, the dispatcher’s tracker queries information from the event source (application specific), and produces scheduling requests based on query results (system logic).
Source: dropbox.com