POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and their Solutions
Table of Contents
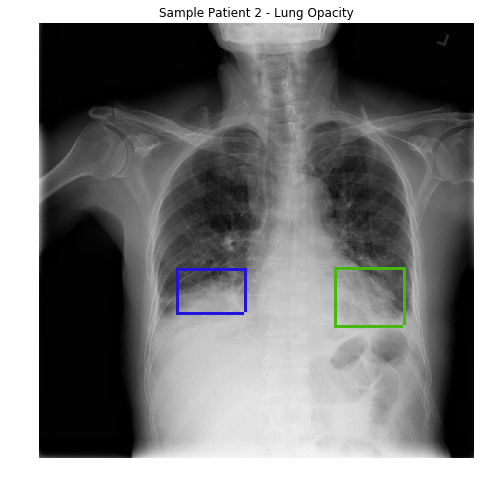
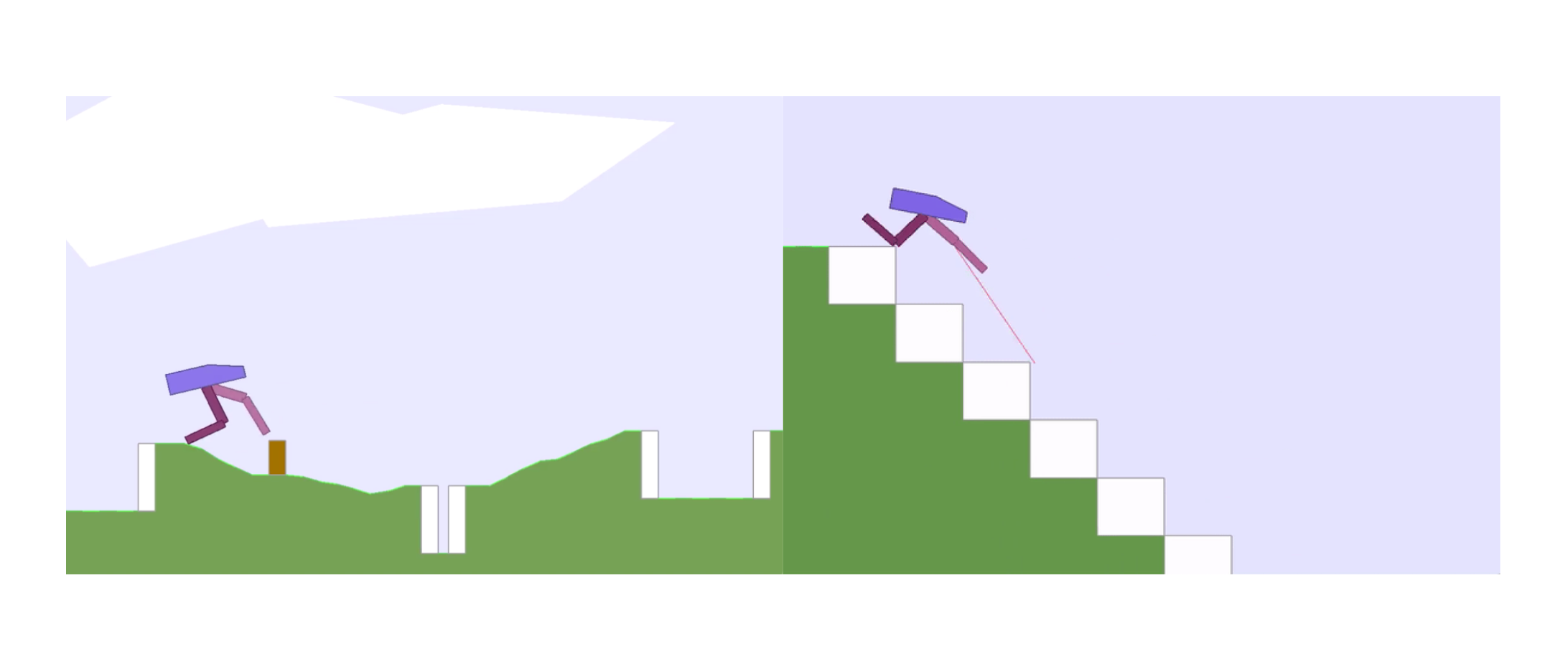
We are interested in open-endedness at Uber AI Labs because it offers the potential for generating a diverse and ever-expanding curriculum for machine learning entirely on its own. Having vast amounts of data often fuels success in machine learning, and we are thus working to create algorithms that generate their own training data in limitless quantities. In the normal practice of machine learning, the researcher identifies a particular problem (for example, a classification problem like ImageNet or a video game like Montezuma’s Revenge) and then focuses on finding or designing an algorithm to achieve top performance.
Sometimes, however, we do not just want to solve known problems, because unknown problems are also important. These might be edge cases (e.g., in safety applications) that are critical to expose (and solve), but they also might be essential stepping stones whose solutions can help make progress on even more challenging problems. Consequently, we are exploring algorithms that continually invent both problems and solutions of increasing complexity and diversity.
Source: uber.com