How Uber Monitors 4,000 Microservices
Table of Contents
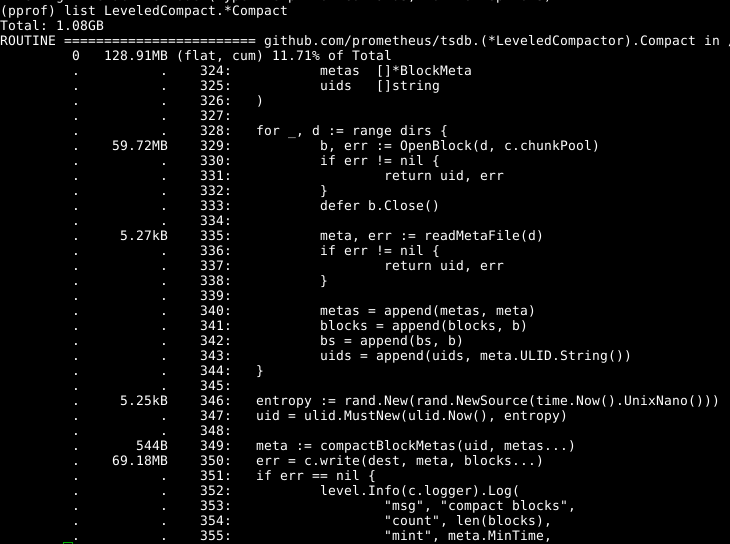
With 4,000 proprietary microservices and a growing number of open source systems that needed to be monitored, by late 2014 Uber was outgrowing its usage of Graphite and Nagios for metrics. They evaluated several technologies, including Atlas and OpenTSDB, but the fact that a growing number of open source systems were adding native support for the Prometheus Metrics Exporter format tipped the scales in that direction. Uber found with its use of Prometheus and M3, Uber’s storage costs for ingesting metrics became 8.53x more cost effective per metric per replica.
The team estimates that setting up monitoring systems in Uber data centers for its Advanced Technologies Group was 4x faster than it would have been under the previous process. Make sure to check out the fullcase study!
Source: cncf.io