Kubernetes Operations: Prioritize Workload in Overcommitted Clusters
Table of Contents
One of the benefits in adopting a system like Kubernetes is facilitating burst-able and scalable workload. Horizontal application scaling involves adding or removing instances of an application to match demand. Kubernetes Horizontal Pod Autoscaler enables automated pod scaling based on demand.
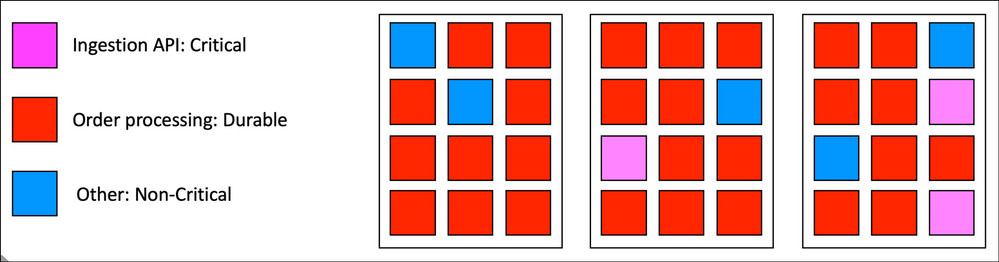
This is cool, however can lead to unpredictable load on the cluster, which may put the cluster into an overcommitted state. The following image represents a three node cluster that runs three applications. Pink is the most critical.
Red is burst-able and durable. This means if we need to stop a few instances of red, things will be ok. Blue is non-critical.
I have also tried to depict in this image a cluster that is a fully maxed out state. Imaging now that a scale out operation is needed on the pink application. This puts the cluster in an overcommitted state with critical workload requiring scheduling.
How can Kubernetes facilitate this critical request in an overcommitted state? One option is to use Pod Priority and Preemption, which allows a priority weight to be added to a scheduling request. In the event of overcommitment, priority is evaluated, and lower priority workload is restarted (preemption) to allow for scheduling of the priority workload.
Source: medium.com