Introducing Ludwig, a Code-Free Deep Learning Toolbox
Table of Contents
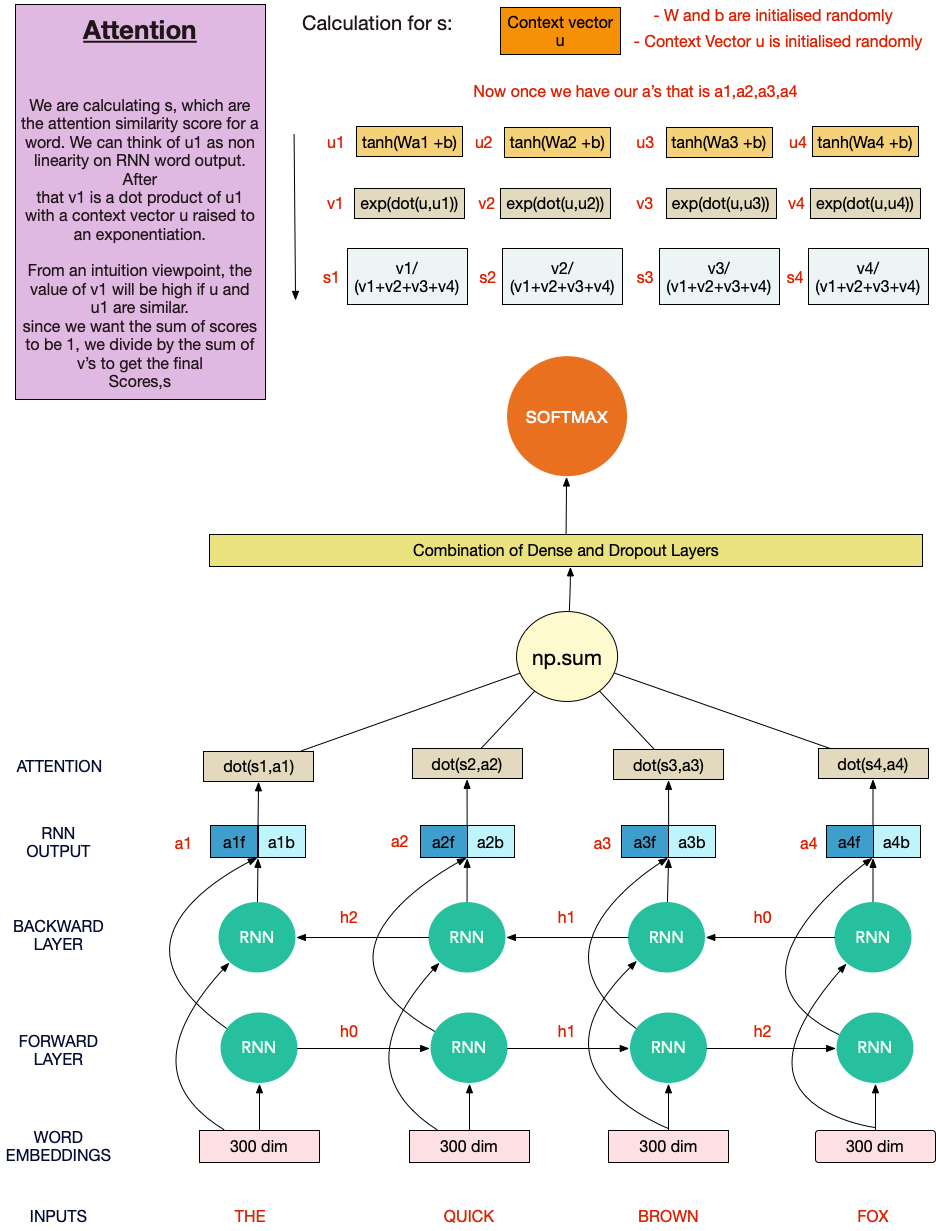
Over the last decade, deep learning models have proven highly effective at performing a wide variety of machine learning tasks in vision, speech, and language. At Uber we are using these models for a variety of tasks, including customer support, object detection, improving maps, streamlining chat communications, forecasting, and preventing fraud. Many open source libraries, including TensorFlow, PyTorch, CNTK, MXNET, and Chainer, among others, have implemented the building blocks needed to build such models, allowing for faster and less error-prone development.
This, in turn, has propelled the adoption of such models both by the machine learning research community and by industry practitioners, resulting in fast progress in both architecture design and industrial solutions. At Uber AI, we decided to avoid reinventing the wheel and to develop packages built on top of the strong foundations open source libraries provide. To this end, in 2017 we released Pyro, a deep probabilistic programming language built on PyTorch, and continued to improve it with the help of the open source community.
Another major open source AI tool created by Uber is Horovod, a framework hosted by the LF Deep Learning Foundation that allows distributed training of deep learning models over multiple GPUs and several machines.
Source: uber.com