Using Machine Learning to Ensure the Capacity Safety of Individual Microservices
Table of Contents
Reliability engineering teams at Uber build the tools, libraries, and infrastructure that enable engineers to operate our thousands of microservices reliably at scale. At its essence, reliability engineering boils down to actively preventing outages that affect the mean time between failures (MTBF). As Uber’s global mobility platform grows, our global scale and complex network of microservice call patterns have made capacity requirements for individual services difficult to predict.
When we’re unable to predict service-level capacity requirements, capacity-related outages can occur. Given the real-time nature of our operations, capacity-related outages (affecting microservices at the feature level as opposed to directly impacting user experiences) constitute a large chunk of Uber’s overall outages. To help prevent these outages, our reliability engineers abide by a concept called capacity safety, in other words, the ability to support historical peaks or a 90-day forecast of concurrent riders-on-trip from a single data center without causing significant CPU, memory, and general resource starvation.
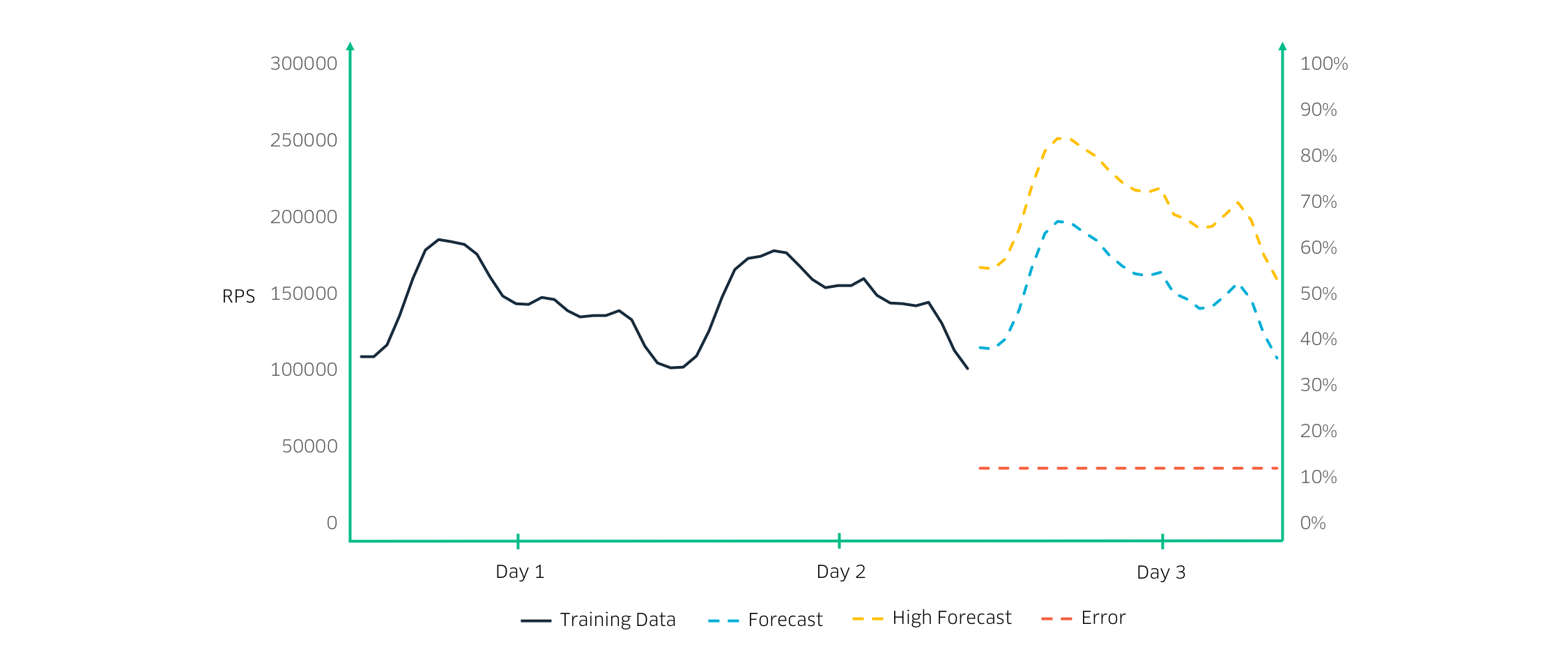
On the Maps Reliability Engineering team, we built in-house machine learning tooling that forecasts core service metrics—requests per second, latency, and CPU usage—to provide an idea of how these metrics will change throughout the course of a week or month. Using these forecasts, teams can perform accurate capacity safety tests that capture the nuances of each microservice.
Source: uber.com


