Aria Presto: Making table scan more efficient
Table of Contents
The Aria is a set of initiatives to dramatically increase PrestoDB efficiency. Our goal is to achieve a 2-3x decrease in CPU time for Hive queries against tables stored in ORC format. For Aria, We are pursuing improvements in three areas: table scan, repartitioning (exchange, shuffle), and hash join.
Nearly 60 percent of our global Presto CPU time is attributed to table scan, making scan improvements high leverage and thus the area we chose to focus on first. Table scan optimizations are specific to queries that access data stored in ORC format but can be extended to support Parquet as well. This post describes how we are making table scan more efficient.
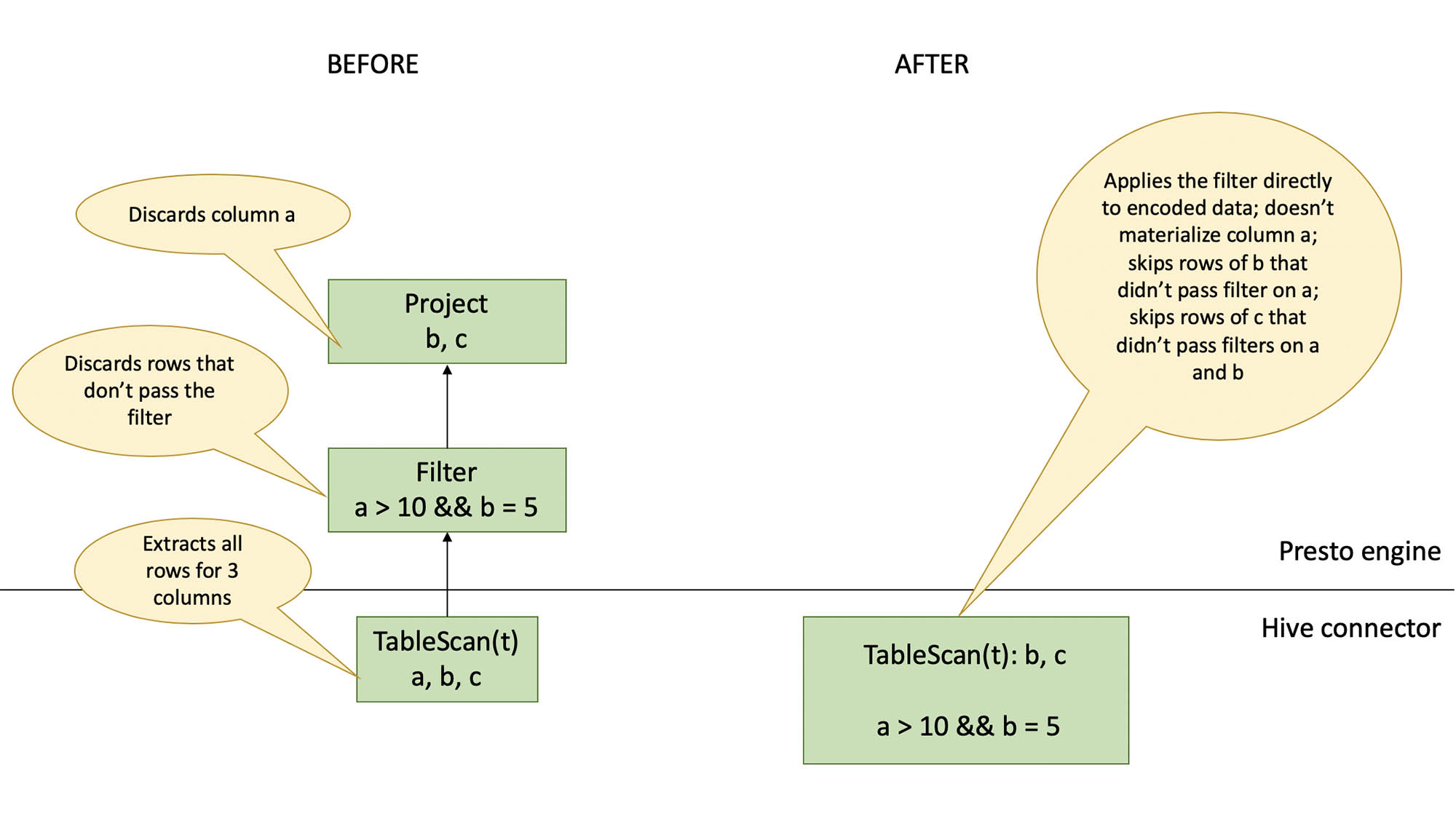
We aim to reduce CPU time by using the following strategies: Subfield pruning: We have large amounts of data stored using complex types: maps, arrays, and structs. Machine learning workloads and various frameworks tend to create very large values, maps with hundreds and sometimes thousands of keys, but the queries access only a handful of these. Extracting these values from ORC files and converting them into Java objects is computationally intensive.
Pruning complex types while extracting data from ORC files can save a lot of CPU cycles. Adaptive filter ordering: Some filters are more efficient than others; they drop more rows in fewer CPU cycles. Today, Presto evaluates filters in the order in which they have been specified in SQL.
Adaptively changing the order in which filters are applied saves CPU cycles by reducing the amount of data that is extracted from the ORC file. Not projecting the columns that are used only to filter data saves CPU cycles as well.
Source: fb.com