MTTR is dead, long live CIRT
Table of Contents
The game is changing for the IT ops community, which means the rules of the past make less and less sense. Organizations need accurate, understandable, and actionable metrics in the right context to measure operations performance and drive critical business transformation. The more customers use modern tools and the more variation in the types of incidents they manage, the less sense it makes to smash all those different incidents into one bucket to compute an average resolution time that will represent ops performance, which is what IT has been doing for a long time.
History shows that context is key when analyzing signals to prevent errors and misunderstandings. For example, during the 1980s, Sweden set up a system to analyze hydrophone signals to alert them to Russian submarines in local Sweden waters. The Swedes used an acoustic signature they thought represented a class of Russian submarines—but was actually gas bubbles released by herring when confronted by a potential predator.
This misinterpretation of a metric increased tensions between the countries and almost resulted in a war.
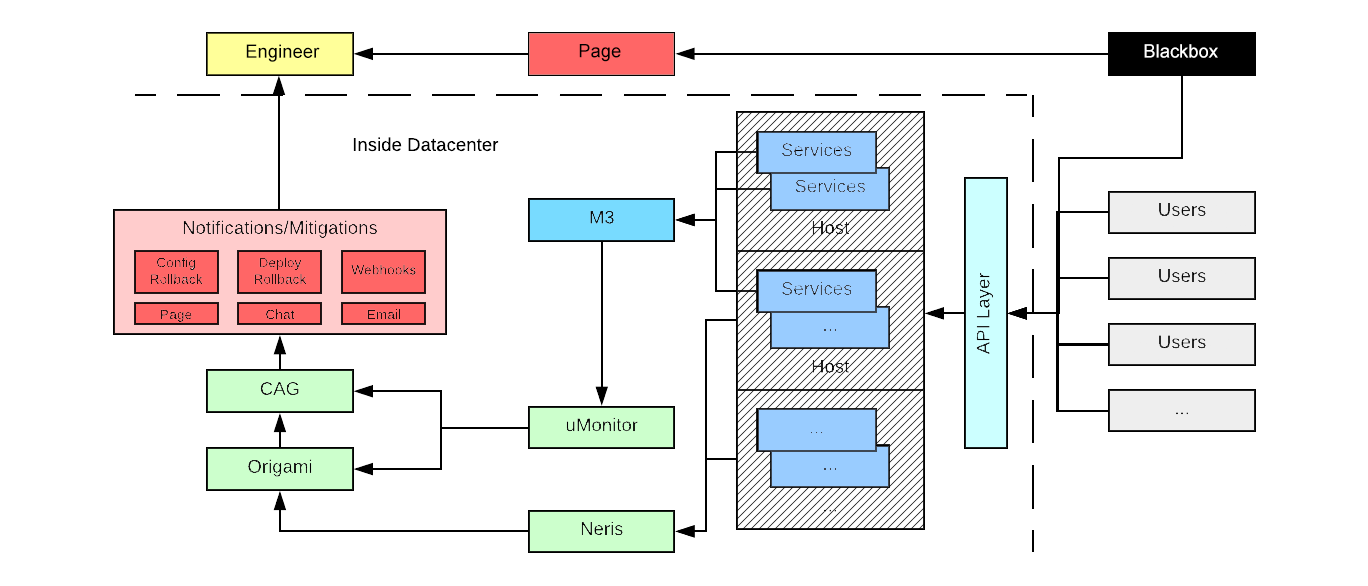
Source: opensource.com