Teaching Computers to Answer Complex Questions
Table of Contents
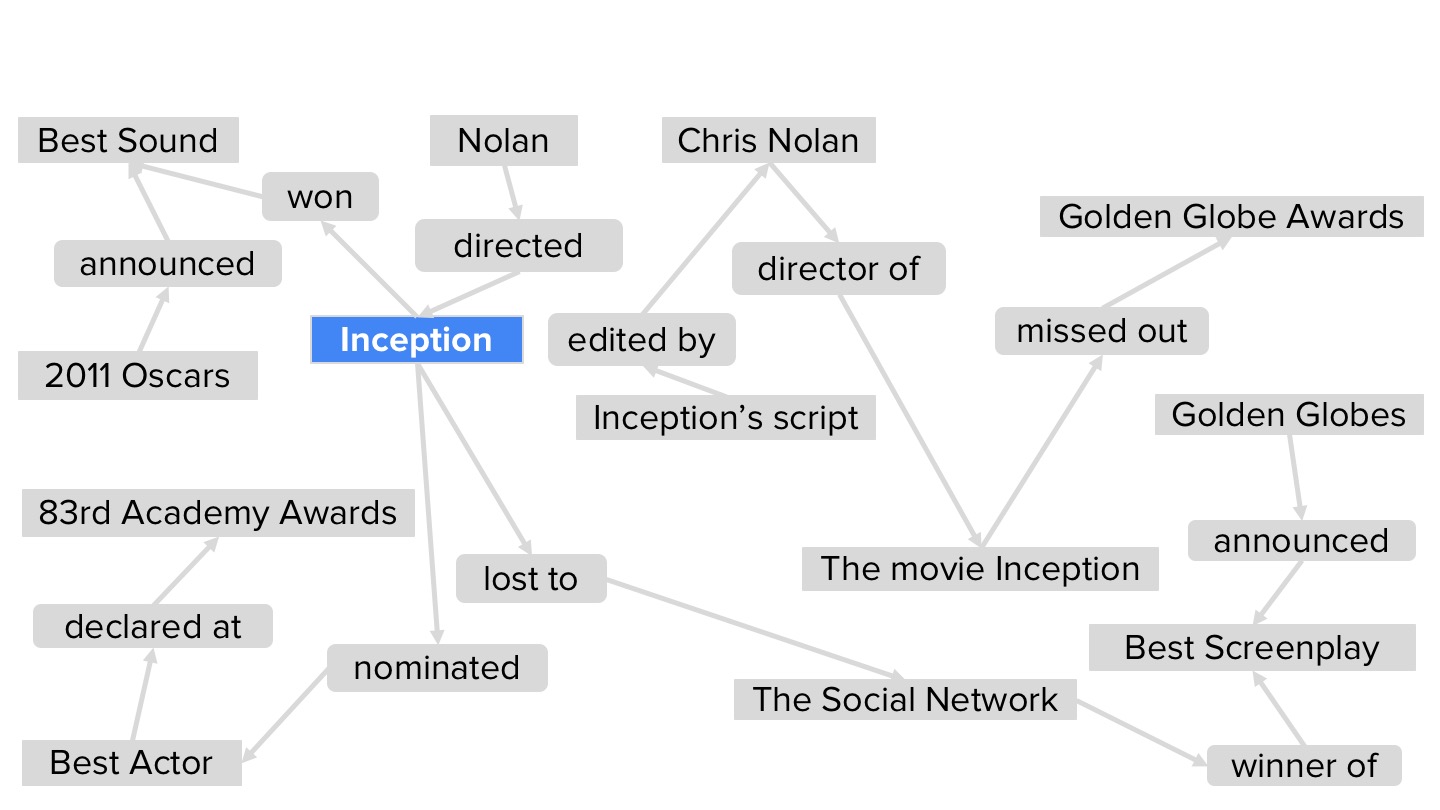
Computerized question-answering systems usually take one of two approaches. Either they do a text search and try to infer the semantic relationships between entities named in the text, or they explore a hand-curated knowledge graph, a data structure that directly encodes relationships among entities. With complex questions, however — such as “Which Nolan films won an Oscar but missed a Golden Globe?” — both of these approaches run into difficulties.
Text search would require a single document to contain all of the information required to satisfy the question, which is highly unlikely. But even if the knowledge graph was up to date, it would have to explicitly represent all the connections established by the question, which is also unlikely. In a paper we presented last week at the ACM’s SIGIR Conference on Research and Development in Information Retrieval, my colleagues and I describe a new approach to answering complex questions that, in tests, demonstrated clear improvements over several competing approaches.
In a way, our technique combines the two standard approaches. On the basis of the input question, we first do a text search, retrieving the 10 or so documents that the search algorithm ranks highest. Then, on the fly, we construct a knowledge graph that integrates data distributed across the documents.
Source: amazon.com