Presto Infrastructure at Lyft
Table of Contents
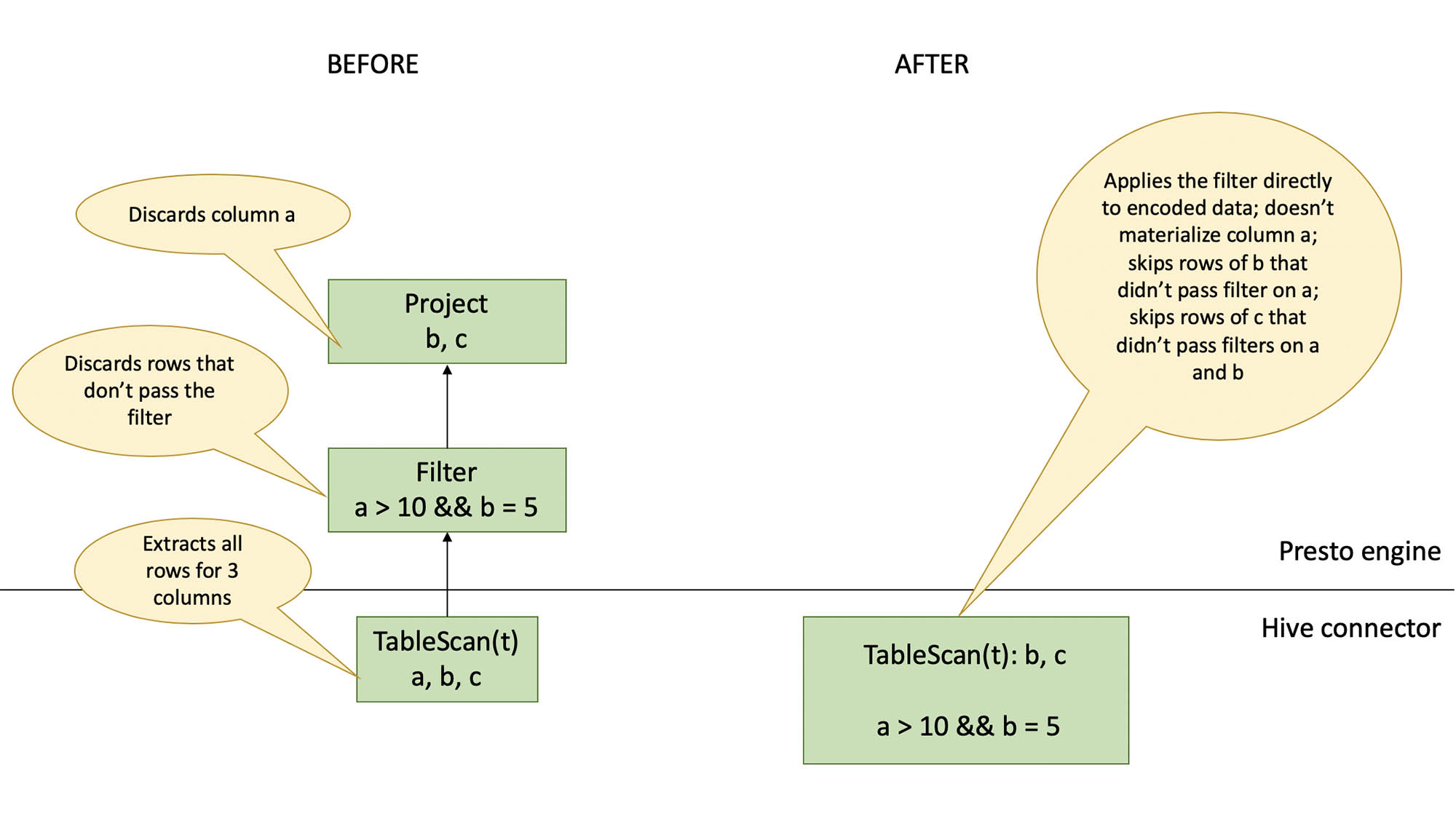
Early in 2017 we started exploring Presto for OLAP use cases and we realized the potential of this amazing query engine. It started as an adhoc querying tool for data engineers and analysts to run SQL in a faster way to prototype their queries, when compared to Apache Hive. A lot of internal dashboards were powered by AWS-Redshift back then and it had data storage and compute coupled together.
Our data was growing exponentially (doubling every few days) this required frequent storage scaling as well. With storage coupled with compute, any maintenance, upgrade required down time, and scaling nodes made querying extremely slow (as massive data moves across nodes), we needed a system where data and compute were decoupled, thats where Presto fit nicely into our use case. A pipeline to store event data in Parquet format had already been setup and data was being accessed via Hive.
Adding Presto to this stack was icing on the cake. Now thousands of dashboards are powered by Presto and about 1.5K weekly active users are running a couple of million queries every month on this platform. As of today we have 60 PB of query-able event data stored in an S3 based data lake and about 10 PB of raw data is being scanned every day using Presto.
Following are the charts showing the timeline of presto usage growth. In the above chart we are looking at raw data scan volume per day. We have seen daily raw data scan volume growing 4X in last 4 months.
Source: lyft.com