Introducing LCA: Loss Change Allocation for Neural Network Training
Table of Contents
Neural networks (NNs) have become prolific over the last decade and now power machine learning across the industry. At Uber, we use NNs for a variety of purposes, including detecting and predicting object motion for self-driving vehicles, responding more quickly to customers, and building better maps. While many NNs perform quite well at their tasks, networks are fundamentally complex systems, and their training and operation is still poorly understood.
For this reason, efforts to better understand network properties and model predictions are ongoing, both at Uber and across the broader scientific community. Although prior studies have analyzed the network training process, it still largely remains a black box: millions of parameters are adjusted via simple rules during training, but our view into the process itself remains limited to a scalar loss quantity, which provides a severely restricted view into a rich and high-dimensional process. For example, it may be that one part of a network is performing all of the learning and another part is useless, but simply observing the loss will never reveal this.
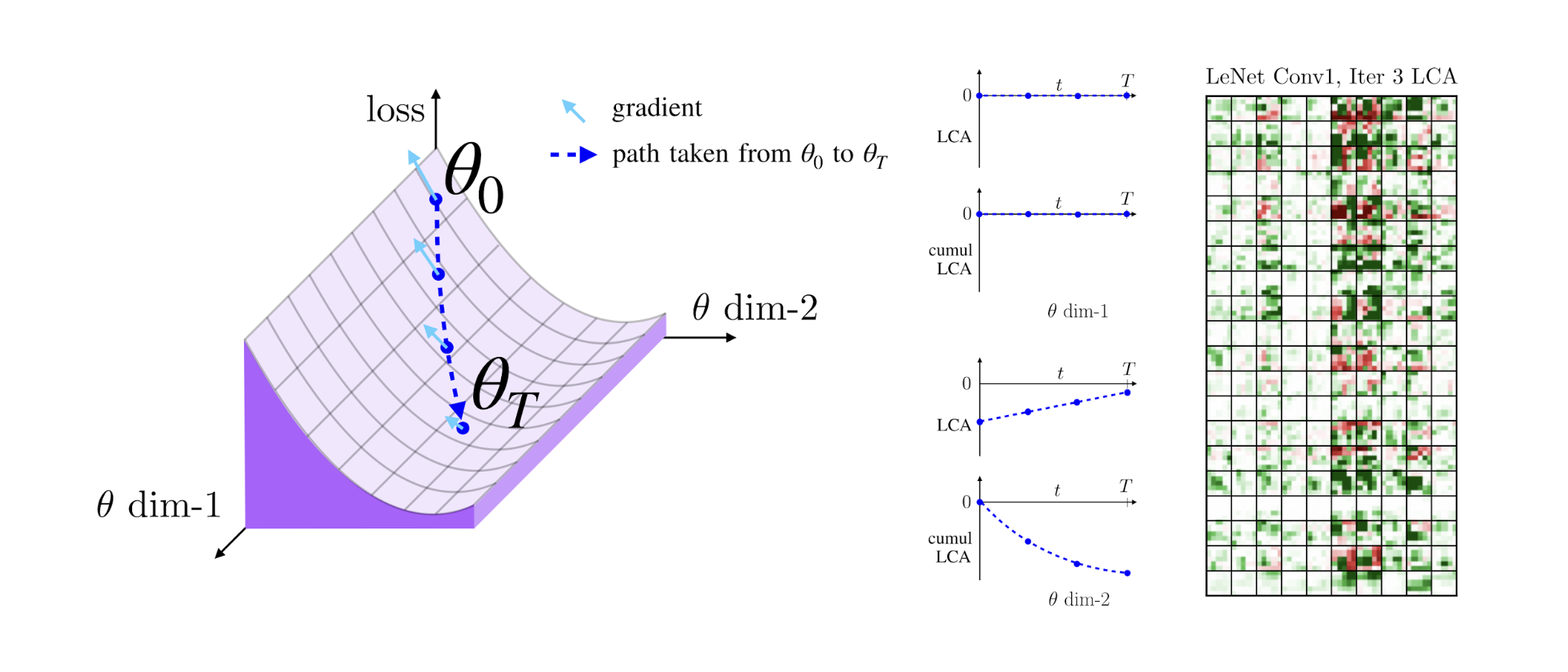
In our paper, LCA: Loss Change Allocation for Neural Network Training, to be presented at NeurIPS 2019, we propose a method called Loss Change Allocation (LCA) that provides a rich window into the neural network training process. LCA allocates changes in loss over individual parameters, thereby measuring how much each parameter learns. Using LCA, we present three interesting observations about neural networks regarding noise, layer contributions, and layer synchronization.
Fellow researchers and practitioners are invited to use our code to try this approach on their own networks.
Source: uber.com