How does a Prometheus Histogram work?
Table of Contents
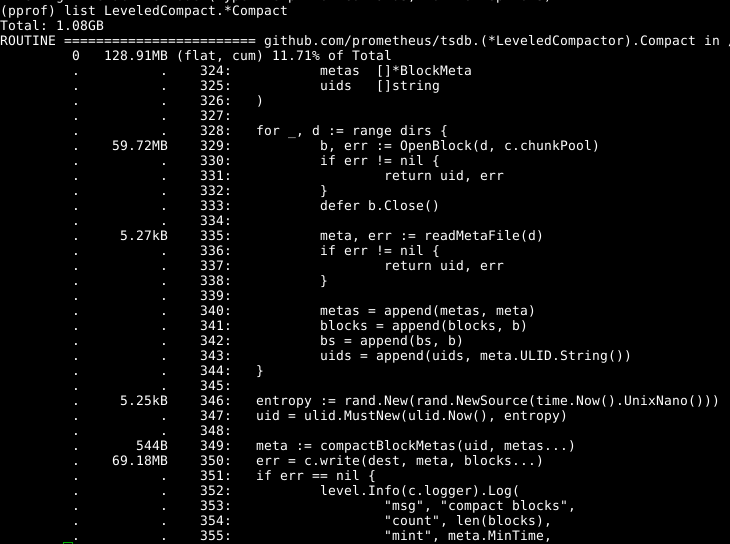
How does a Prometheus Histogram work? We looked previously at thecounter, gauge, and summary, how does the Prometheus histogram work? The histogram has several similarities to the summary.
A histogram is a combination of various counters. Like summary metrics, histogram metrics are used to track the size of events, usually how long they take, via their observe method. There’s usually also the exact utilities to make it easy to time things as there are for summarys.
Where they differ is their handling of quantiles.
Source: robustperception.io