The Dark Secrets Of BERT
Table of Contents
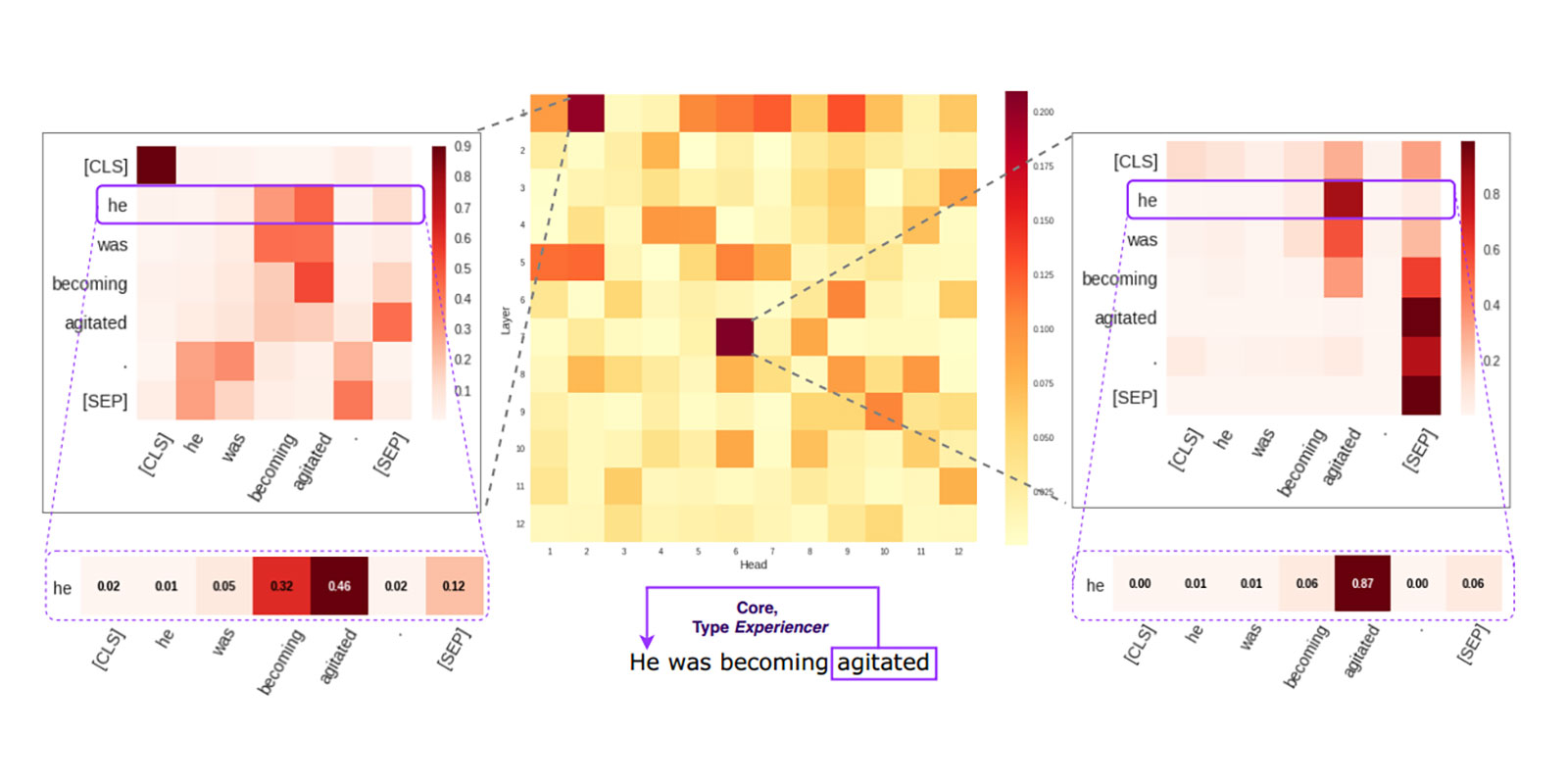
BERT stands for Bidirectional Encoder Representations from Transformers. This model is basically a multi-layer bidirectional Transformer encoder(Devlin, Chang, Lee, & Toutanova, 2019), and there are multiple excellent guides about how it works generally, includingthe Illustrated Transformer. What we focus on is one specific component of Transformer architecture known as self-attention.
In a nutshell, it is a way to weigh the components of the input and output sequences so as to model relations between them, even long-distance dependencies. As a brief example, let’s say we need to create a representation of the sentence “Tom is a black cat”. BERT may choose to pay more attention to “Tom” while encoding the word “cat”, and less attention to the words “is”, “a”, “black”.
This could be represented as a vector of weights (for each word in the sentence). Such vectors are computed when the model encodes each word in the sequence, yielding a square matrix which we refer to as the self-attention map.
Source: topbots.com

