Train ALBERT for natural language processing with TensorFlow on Amazon SageMaker
Table of Contents
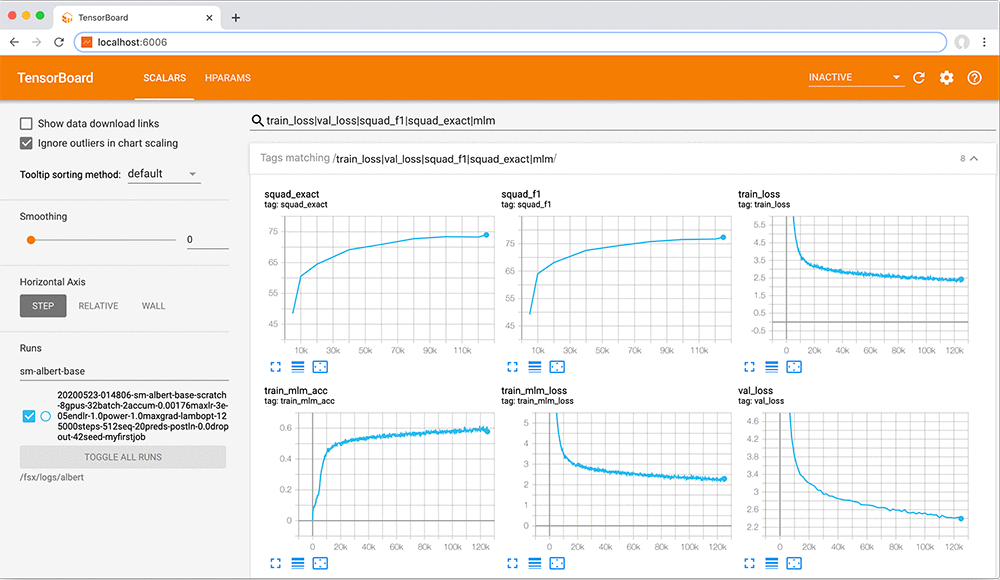
At re:Invent 2019, AWSsharedthe fastest training times on the cloud for two popular machine learning (ML) models: BERT (natural language processing) and Mask-RCNN (object detection). To train BERT in 1 hour, we efficiently scaled out to 2,048 NVIDIA V100 GPUs by improving the underlying infrastructure, network, and ML framework. Today, we’re open-sourcing the optimized training codefor ALBERT (A Lite BERT), a powerful BERT-based language modelthat achieves state-of-the-art performanceon industry benchmarks while training 1.7 times faster and cheaper.
This post demonstrates how to train a faster, smaller, higher-quality model called ALBERT on Amazon SageMaker, a fully managed service that makes it easy to build, train, tune, and deploy ML models. Although this isn’t a new model, it’s the first efficient distributed GPU implementation for TensorFlow 2. You can use AWS training scripts to train ALBERT inAmazon SageMakeron p3dn and g4dn instances for both single-node and distributed training.
The scripts use mixed-precision training and accelerated linear algebra to complete training in under 24 hours(five times faster than without these optimizations), which allows data scientists to iterate faster and bring their models to production sooner. It uses model architectures fromthe open-source Hugging Facetransformerslibrary. For more information, seethe GitHub repo.
Source: amazon.com


