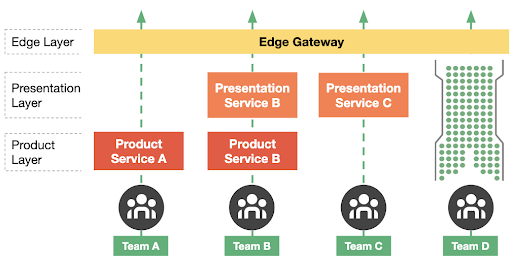
Engineering For Failure
Table of Contents
A set of practical patterns to recover from failures in external services Not so long ago, our systems were simple: we had one machine, with one process, probably no more than one external datastore, and the entire request lifecycle was processed and handled within this simple world. Our users were also accustomed to a certain SLA standard — a 2-second page load time could have been acceptable a few years ago, but waiting more than a second for an Instagram post is unthinkable nowadays. When systems get more complex, with strict latency requirements and a distributed infrastructure, an uninvited guest crawls up our systems — request failure.
Source: medium.com