Production testing with dark canaries
Table of Contents
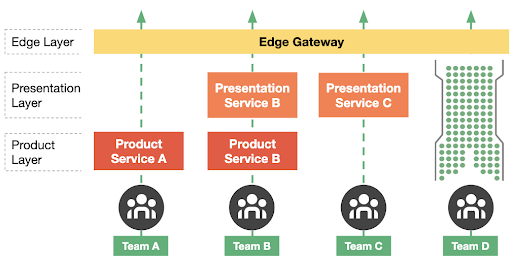
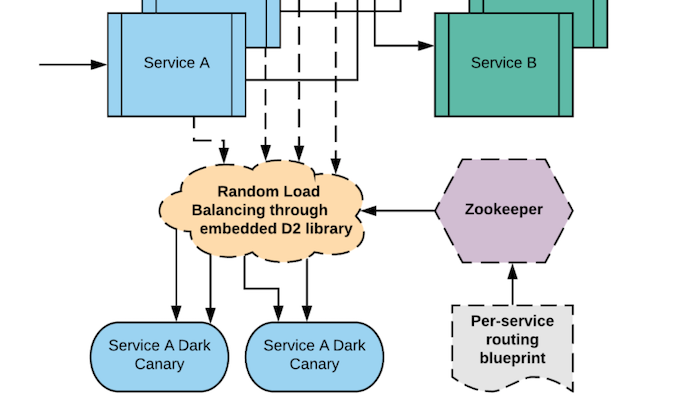
Back in 2013, one of our large backend services wanted support in Rest.li for dark canaries. The service, at the time, involved duplicating requests from one host machine and sending it to another host machine. This was added via a Python tool to populate the host-to-host mapping in Apache ZooKeeper along with a filter to read this mapping and multiply traffic.
As operational complexity grew (due to additional data centers, dark canaries being used in midtier and even frontend services, and dynamic scale up-down of instances), this became more complex to maintain. More teams were using dark canaries, but our developers and SREs were still hindered by how difficult it was to onboard and maintain dark canaries. For example, when dark canaries suddenly stopped receiving traffic or disappeared because hosts were swapped out from underneath them, engineers had to recreate the tedious host-to-host mapping in every data center.
It was clear we needed a new solution.
Source: linkedin.com