VINE: An Open Source Interactive Data Visualization Tool for Neuroevolution
Table of Contents
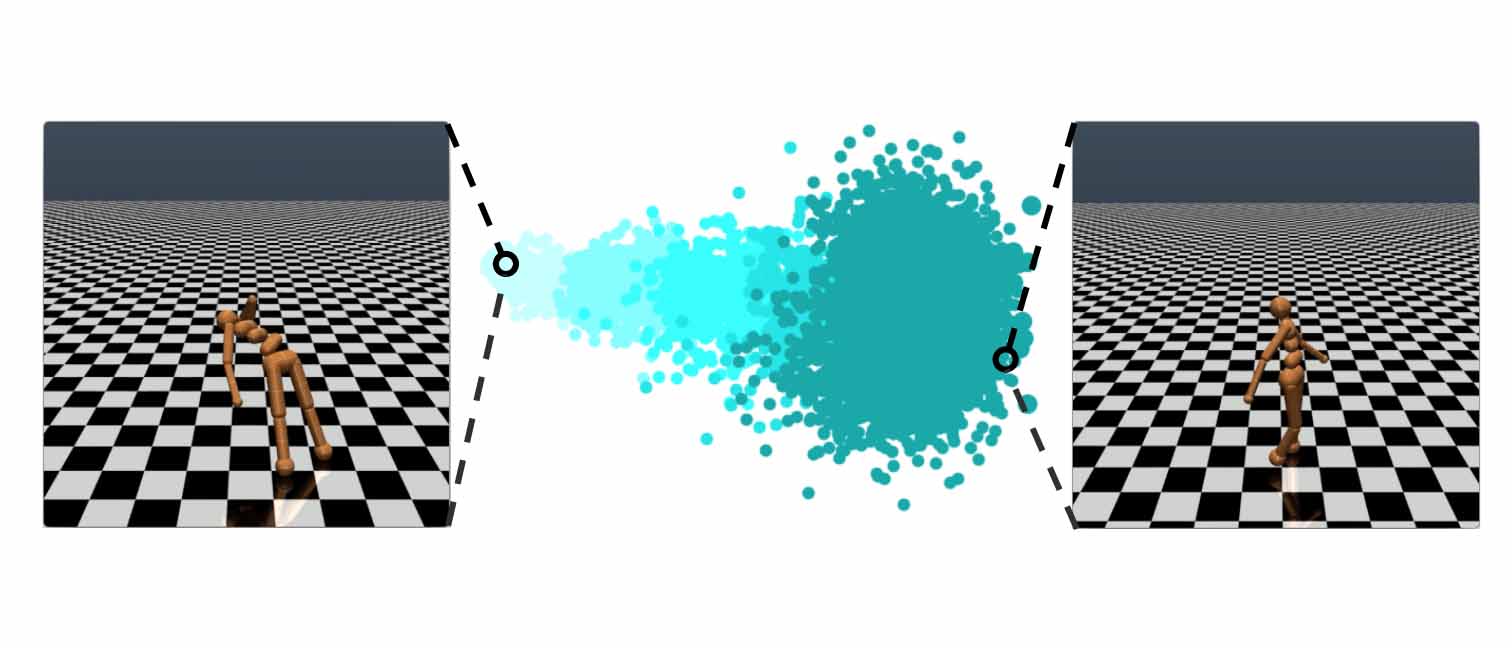
Uber AI Labs introduces Visual Inspector for Neuroevolution (VINE), an open source interactive data visualization tool to help neuroevolution researchers better understand this family of algorithms.
Source: uber.com


