Accurate Online Speaker Diarization with Supervised Learning
Table of Contents
![]()
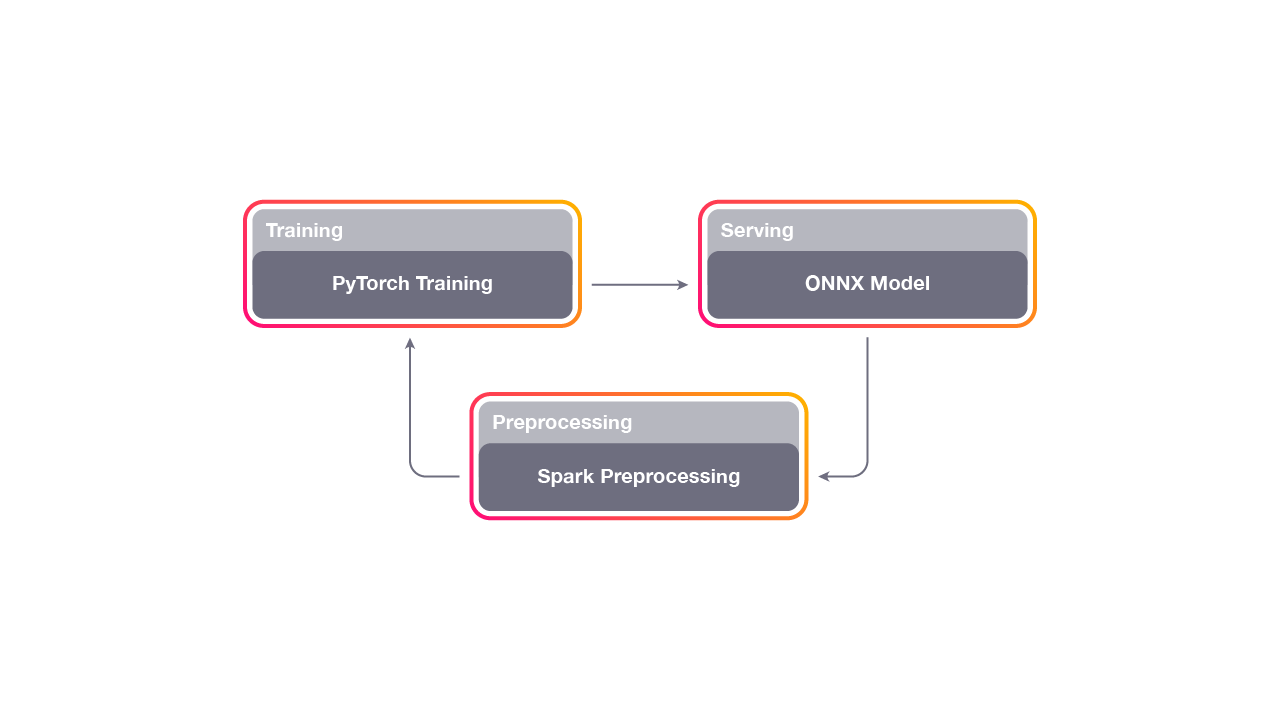
Speaker diarization, the process of partitioning an audio stream with multiple people into homogeneous segments associated with each individual, is an important part of speech recognition systems. By solving the problem of “who spoke when”, speaker diarization has applications in many important scenarios, such as understanding medical conversations, video captioning and more. However, training these systems with supervised learning methods is challenging — unlike standard supervised classification tasks, a robust diarization model requires the ability to associate new individuals with distinct speech segments that weren’t involved in training.
Importantly, this limits the quality of both online and offline diarization systems. Online systems usually suffer more, since they require diarization results in real time.
Source: googleblog.com