Disaster Tolerance Patterns Using AWS Serverless Services
Table of Contents
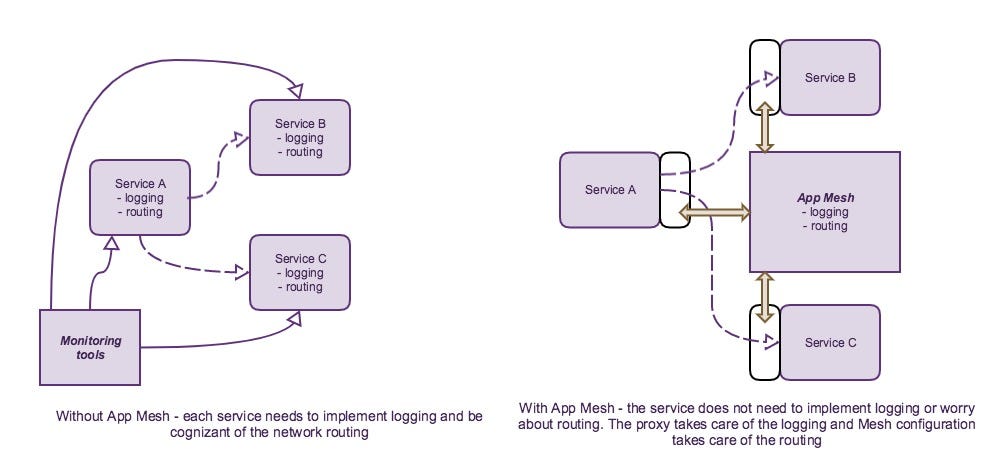
In my previous post (Disaster Recovery for Cloud Solutions is Obsolete) I asserted that you should design your cloud architectures for Disaster Tolerance from the start (even if it is counter intuitive to do so by lean principles). I also argued that you should do this because it’s easy if you do it now, and it will help your business even if there is never a disaster.
The problem is that while that’s all true, in practice there are enough gotchas that what should be easy can take you down a lot of rabbit holes before you get to where you need to be. I’ve recently gone through the exercise for my current startup (Cloud Pegboard) and would like to share those learnings so that you get the benefits of what’s possible without having the go down and back from dead ends in the maze. Okay, here’s our challenge: create a new SaaS service on AWS that delights users, make it highly available even if there is a disaster or failure of the scale to knock out an entire AWS region or an entire service within the region, and do all this with minimal extra effort and expense to create and operate the service.
We’re a startup, so we need to focus most of our attention on delivering user value but are confident enough on our future success that we know we don’t want to create a heap of technical debt that could have been readily avoided with just a little foresight. Disaster Tolerance is the characteristic of a complete operational solution to withstand large scale faults without requiring any (or at least any significant) manual intervention. Disaster Tolerance is fault tolerance expanded to cover disaster level (e.g., region failure) faults.
Disaster Tolerance contrasts with Disaster Recovery which is an approach that reacts to a disaster incident by executing a set of one-time “recovery” procedures to restore service.
Source: medium.com