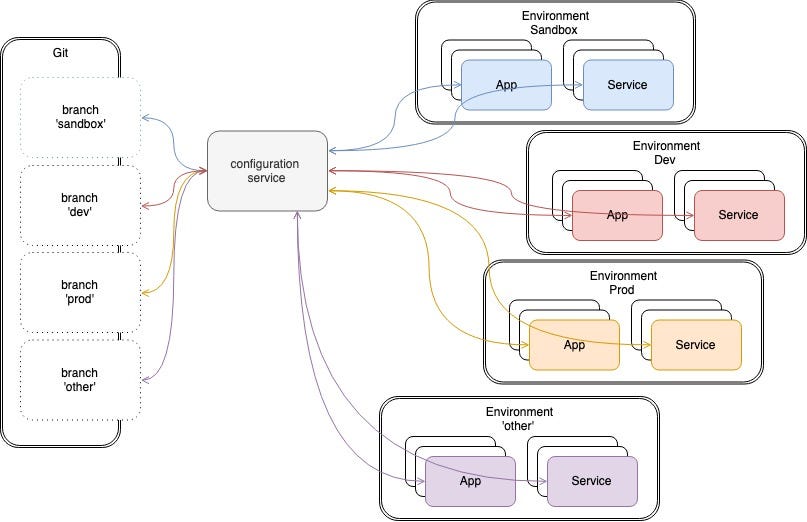
A standard way of managing configurations for multiple environments (and clouds)
Table of Contents
This article intended to share ideas and solutions to address some challenges related to Configuration Management, especially in the cloud environment. Hope you find this read helpful. The approach described in this article was conceptualized a few years back, then implemented and used across many, many projects to build configuration management components for production-grade systems and applications.
This problem is quite common and we have seen it over the years not only in cloud-based deployments and environments but also in the local type of deployments, similar to “3 blades in the rack next room”. This problem is applicable to any deployment with more than 1 environment in the picture, like DEV, QA, STG, PROD and so on. And the problem is, as you probably have guessed, the configuration data and its management.
Wiki talks about Configuration Management(CM) in great length – CM planning and management, controls, status, so on and so forth, but I’m as architect and DevOps engineer always about the details (well, that’s where you-know-who is..) and about how to get this done in fastest and most efficient way.
Source: itnext.io