Making the LinkedIn experimentation engine 20x faster
Table of Contents
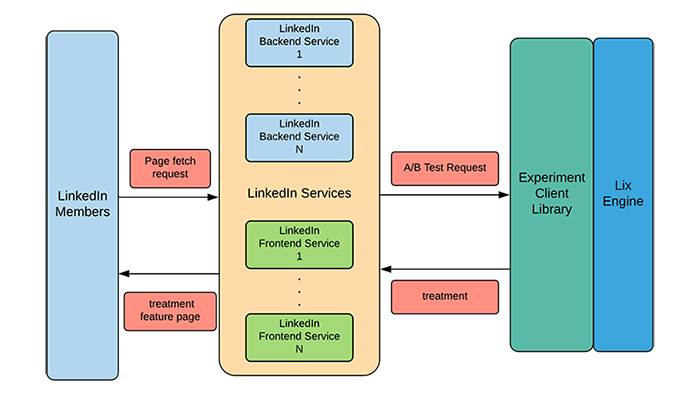
At LinkedIn, we like to say that experimentation is in our blood because no production release at the company happens without experimentation; by “experimentation,” we typically mean “A/B testing.” The company relies on employees to make decisions by analyzing data. Experimentation is a data-driven foundation of the decision-making process, which helps with measuring the precise impact of every change and release, and evaluating whether expectations meet reality.
LinkedIn’s experimentation platform operates at an extremely large scale: It serves up to 800,000 QPS of network calls, It serves about 35,000 concurrently running A/B experiments, It handles up to 23 trillion experiment evaluations per day, Average latency of experiment evaluation is 700 ns and the 99th percentile is 3 μs, It is used in about 500 production services. It is used in about 500 production services.
Source: linkedin.com


