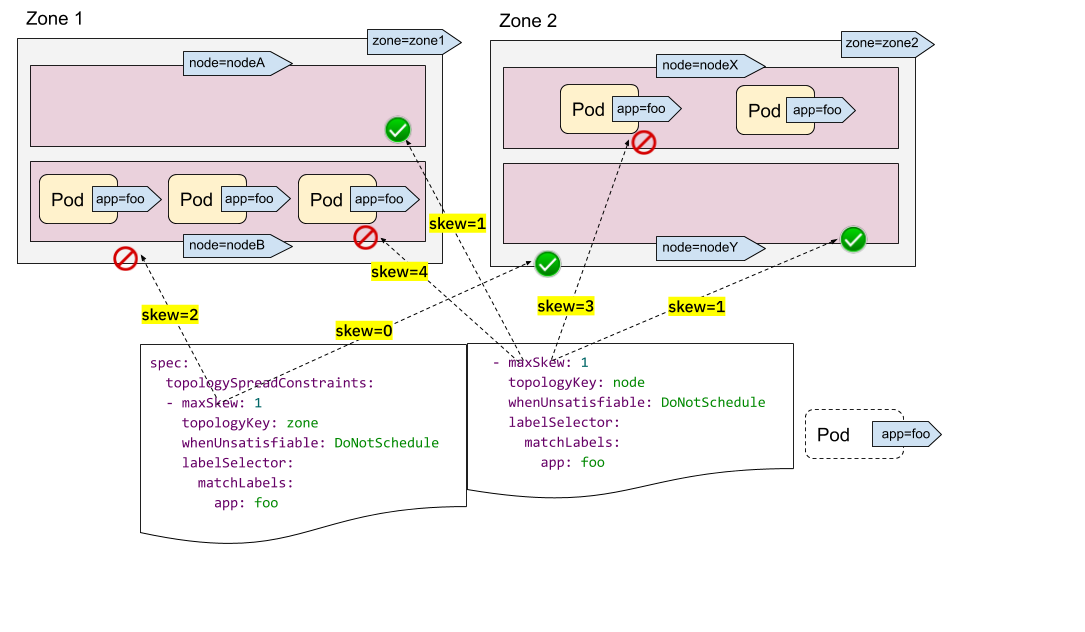
Ingress for Anthos—Multi-cluster Ingress and Global Service Load Balancing
Table of Contents
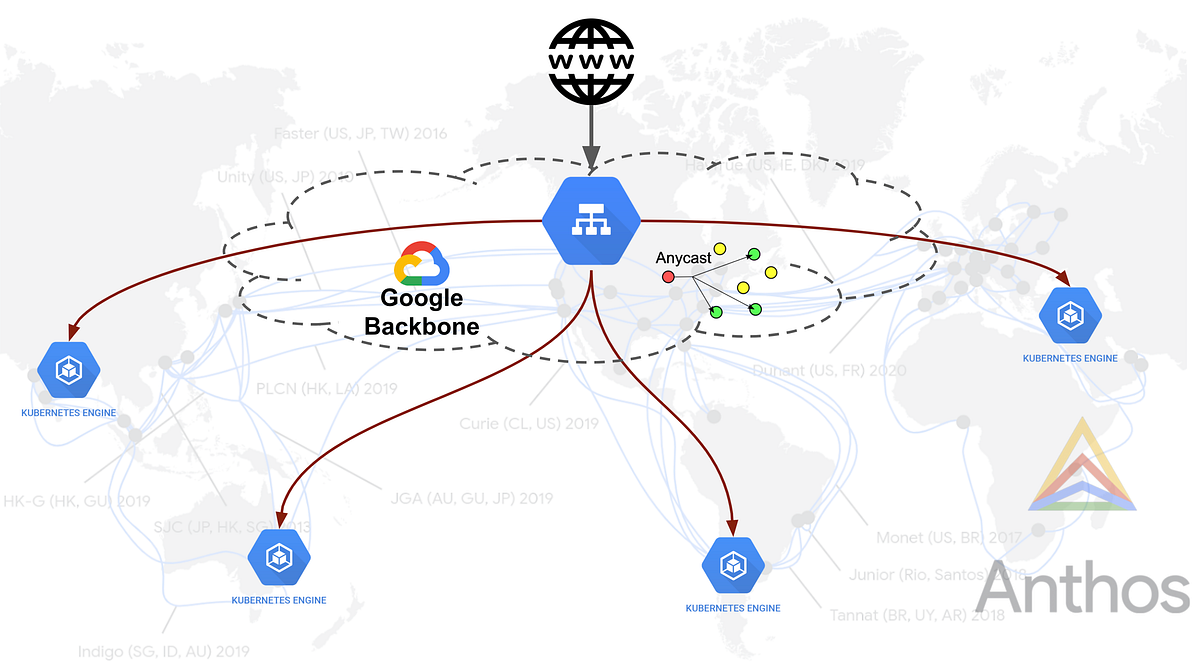
Ingress for Anthos is a Google cloud-hosted multi-cluster ingress controller for Anthos GKE clusters. Ingress for Anthos supports deploying shared load balancing resources across clusters and across regions enabling users to use a same load balancer with an anycast IP for applications running in a multi-cluster and multi-region topology. In simpler terms this allows users to place multiple GKE clusters located in different regions under one LoadBalancer.
It’s a controller for the external HTTP(S) load balancer to provide ingress for traffic coming from the internet across one or more clusters by programming the external HTTP(S) load balancer using network endpoint groups (NEGs). NEGs are useful for Container native load balancing where each Container can be represented as endpoint to the load balancer. Taking advantage of GCP’s 100+ Points of Presence and global network, Ingress for Anthos leverage GCLB along with multiple Kubernetes Engine clusters running across regions around the world, to serve traffic from the closest cluster using a single anycast IP address.
Source: itnext.io