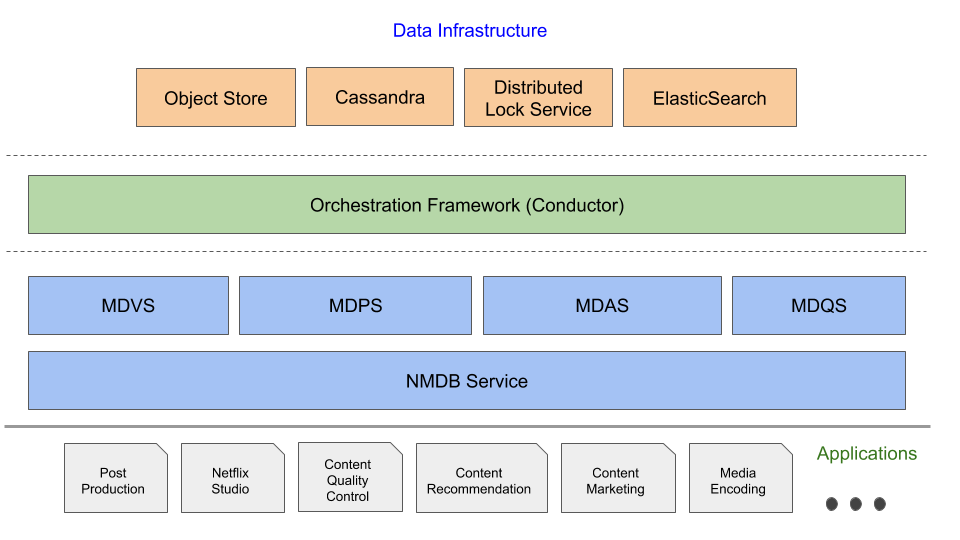
Implementing the Netflix Media Database
In the previous blog posts in this series, we introduced the Netflix Media DataBase (NMDB) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements—these will serve as the necessary motivation for the architectural choices we made. A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve.
Read More

Optimal Shard Placement in a Petabyte Scale Elasticsearch Cluster
The number of shards on each node, and tries to balance the number of shards per node evenly across the clusterThe high and low disk watermarks. Elasticsearch considers the available disk space on a node before deciding whether to allocate new shards to that node or to actively relocate shards away from that node. A nodes that has reached the low watermark (i.e 80% disk used) is not allowed receive any more shards.
Read More
Cross shard transactions at 10 million requests per second
Dropbox stores petabytes of metadata to support user-facing features and to power our production infrastructure. The primary system we use to store this metadata is named Edgestore and is described in a previous blog post, (Re)Introducing Edgestore. In simple terms, Edgestore is a service and abstraction over thousands of MySQL nodes that provides users with strongly consistent, transactional reads and writes at low latency.
Read More
Tech’s Next Big Wave: Big Data Meets Biology
The quest to retrieve, analyze, and leverage that data has become the new gold rush. And a vanguard of tech titans—not to mention a bevy of hot startups—are on the hunt for it.
Read More