GraphQL: A success story for PayPal Checkout
Table of Contents
At PayPal, we recently introduced GraphQL to our technology stack. At PayPal, GraphQL has been a complete game changer to the way we think about data, fetch data and build applications. This blog post takes a close look at PayPal Checkout and explains our journey from REST to Batch REST to GraphQL and lessons learned along the way.
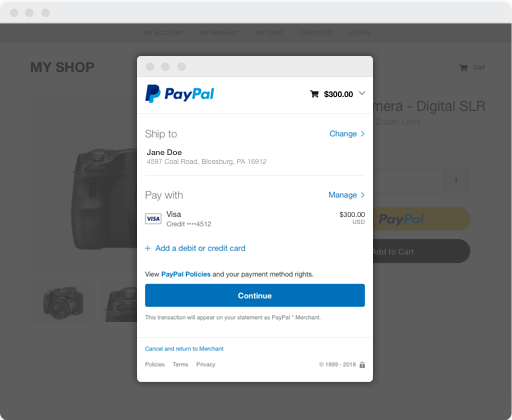
PayPal’s Checkout products spread across many web and mobile apps, supporting millions of users across ~200 countries and has hundreds of experiments running at any time. These apps leverage the same suite of REST APIs to fetch data needed for building UI. About 4 years ago, we went all in on REST.
Our APIs were pretty clean, small and atomic. Things were great in the beginning. REST has strict design principles that are widely understood.
REST is a great way to design and implement APIs for your domain. However, REST’s principles don’t consider the needs of Web and Mobile apps and their users. This is especially true in an optimized transaction like Checkout.
Users want to complete their checkout as fast as possible. If your applications are consuming atomic REST APIs, you’re often making many round trips from the client to the server to fetch data. With Checkout, we’ve found that every round trip costs at least 700ms in network time (at the 99th percentile), not counting the time processing the request on the server.
Every round trip results in slower rendering time, more user frustration and lower Checkout conversion. Needless to say, round trips are evil!
Source: medium.com