Five Lessons From the First Three Years of Michelangelo
Table of Contents
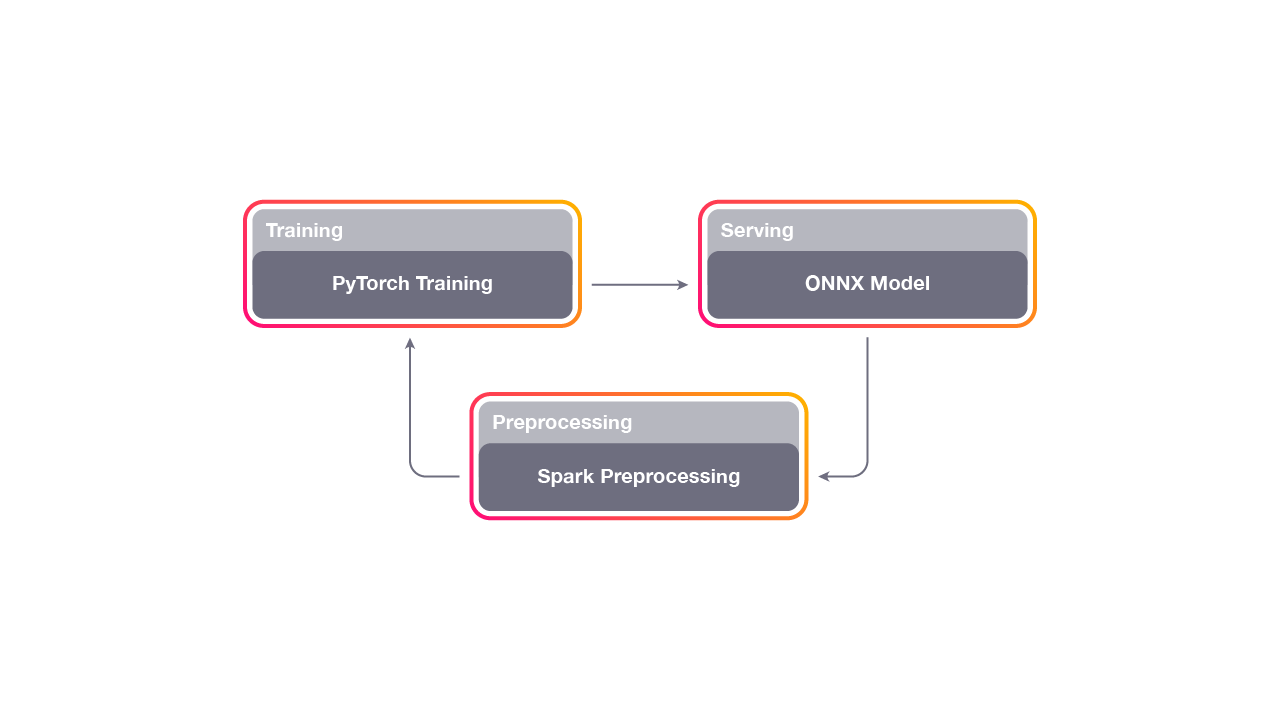
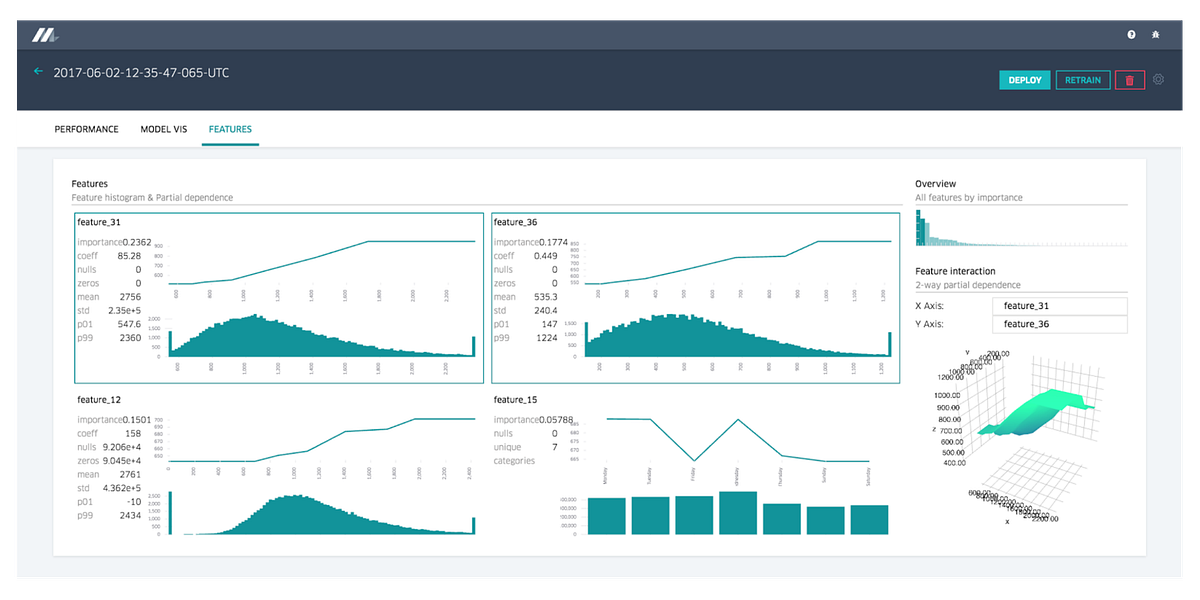
Uber has been one of the most active contributors to open source machine learning technologies in the last few years. While companies like Google or Facebook have focused their contributions in new deep learning stacks like TensorFlow, Caffe2 or PyTorch, the Uber engineering team has really focused on tools and best practices for building machine learning at scale in the real world. Technologies such as Michelangelo, Horovod, PyML, Pyro are some of examples of Uber’s contributions to the machine learning ecosystem.
With only a small group of companies developing large scale machine learning solutions, the lessons and guidance from Uber becomes even more valuable for machine learning practitioners (I certainly learned a lot and have regularly written about Uber’s efforts). Recently, the Uber engineering team published an evaluation of the first three years of operations of the Michelangelo platform. If we remove all the Michelangelo specifics, Uber’s post contains a few non-obvious, valuable lessons for organizations starting in their machine learning journey.
I am going to try to summarize some of those key takeaways in a more generic way that can be applicable to any mainstream machine learning scenario.
Source: towardsdatascience.com