Lyft’s Journey through Mobile Networking
Table of Contents
In 5 years, the number of endpoints consumed by Lyft’s mobile apps grew to over 500, and the size of our mobile engineering team increased by more than 15x. To scale with this growth, our infrastructure had to evolve dramatically to utilize new advances in modern networking in order to continue to provide benefits for our users. This post describes the journey through the evolution of Lyft’s mobile networking: how it’s changed, what we’ve learned, and why it’s important for us as a growing business.
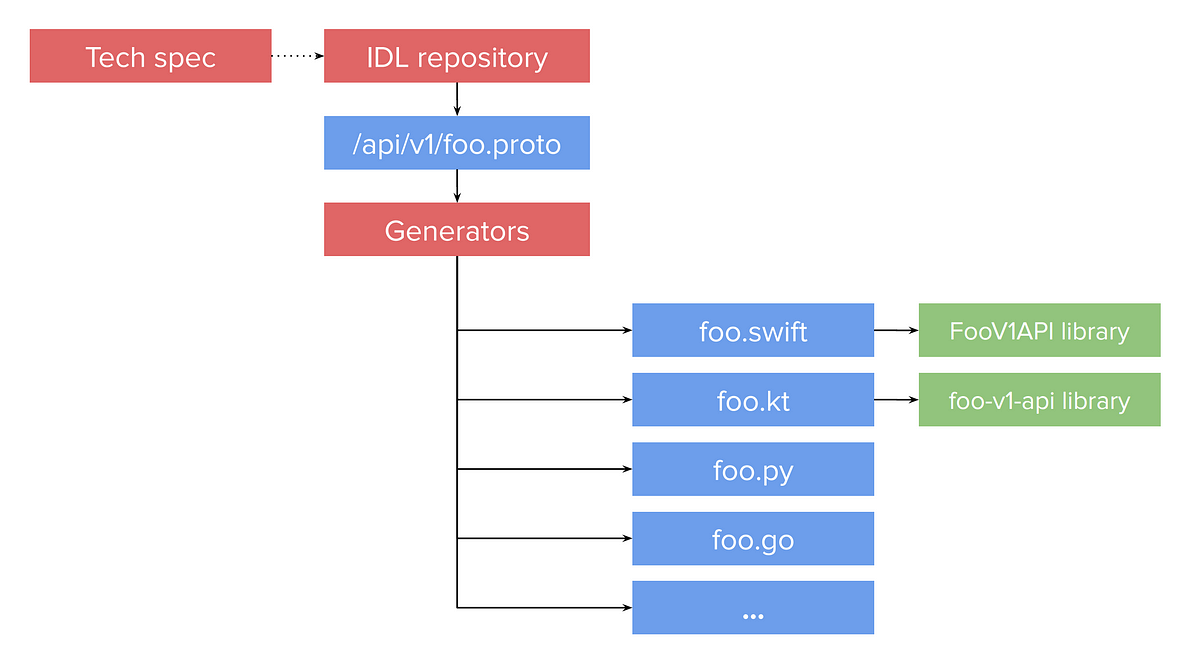
The early iterations of the Lyft apps used commonly known networking frameworks like URLSession on iOS and OkHttp on Android. All of our APIs were JSON over RESTful HTTP. The workflow for developing an endpoint looked something like the following diagram, where engineers hand-wrote APIs on each platform based on a tech spec:
Source: lyft.com