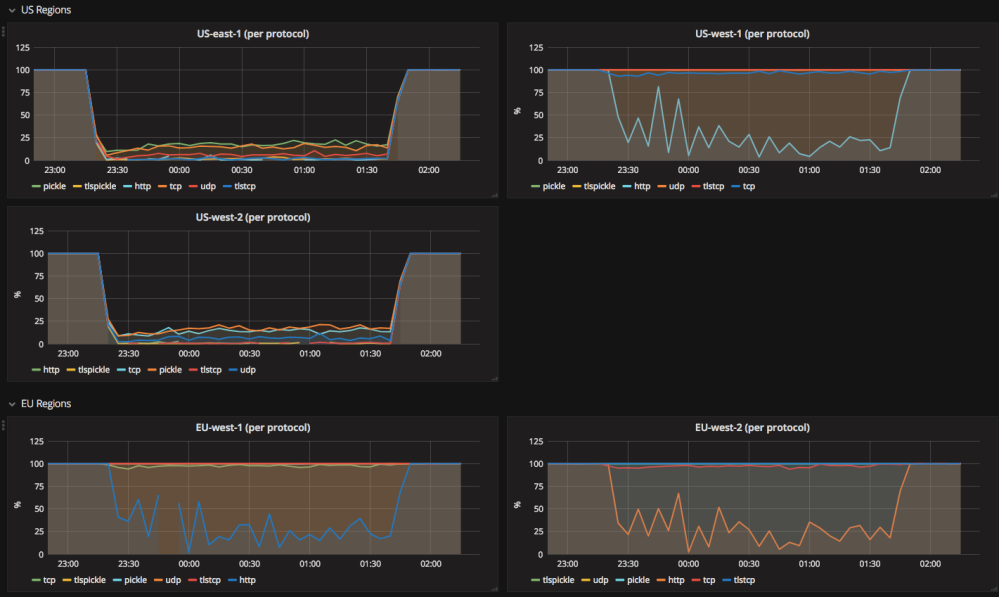
Cross shard transactions at 10 million requests per second
Dropbox stores petabytes of metadata to support user-facing features and to power our production infrastructure. The primary system we use to store this metadata is named Edgestore and is described in a previous blog post, (Re)Introducing Edgestore. In simple terms, Edgestore is a service and abstraction over thousands of MySQL nodes that provides users with strongly consistent, transactional reads and writes at low latency.
Read More
A Netflix Web Performance Case Study
Netflix is one of the most popular video streaming services. Since launching globally in 2016, the company has found that many new users are not only signing up on mobile devices but are also using less-than-ideal connections to do so. By refining the JavaScript used for Netflix.com’s sign-up process and using prefetching techniques, the developer team was able to provide a better user experience for both mobile and desktop users and offer several improvements.
Read More

Multi-Cloud Is a Trap
It comes up in a lot of conversations with clients. We want to be cloud-agnostic. We need to avoid vendor lock-in.
Read More
M3: Uber’s Open Source Large-Scale Metrics Platform for Prometheus
M3, Uber’s open source metrics platform for Prometheus, facilitates scalable and configurable multi-tenant storage for large-scale metrics. To facilitate the growth of Uber’s global operations, we need to be able to quickly store and access billions of metrics on our back-end systems at any given time. As part of our robust and scalable metrics infrastructure, we built M3, a metrics platform that has been in use at Uber for several years now.
Read More
Serverless Performance: Cloudflare Workers, Lambda and Lambda@Edge
A few months ago we released a new way for people to run serverless Javascript called Cloudflare Workers. We believe Workers is the fastest way to execute serverless functions, but lets prove it. At the 95th percentile, Workers is 441% faster than a Lambda function, and 192% faster than Lambda@Edge.
Read More

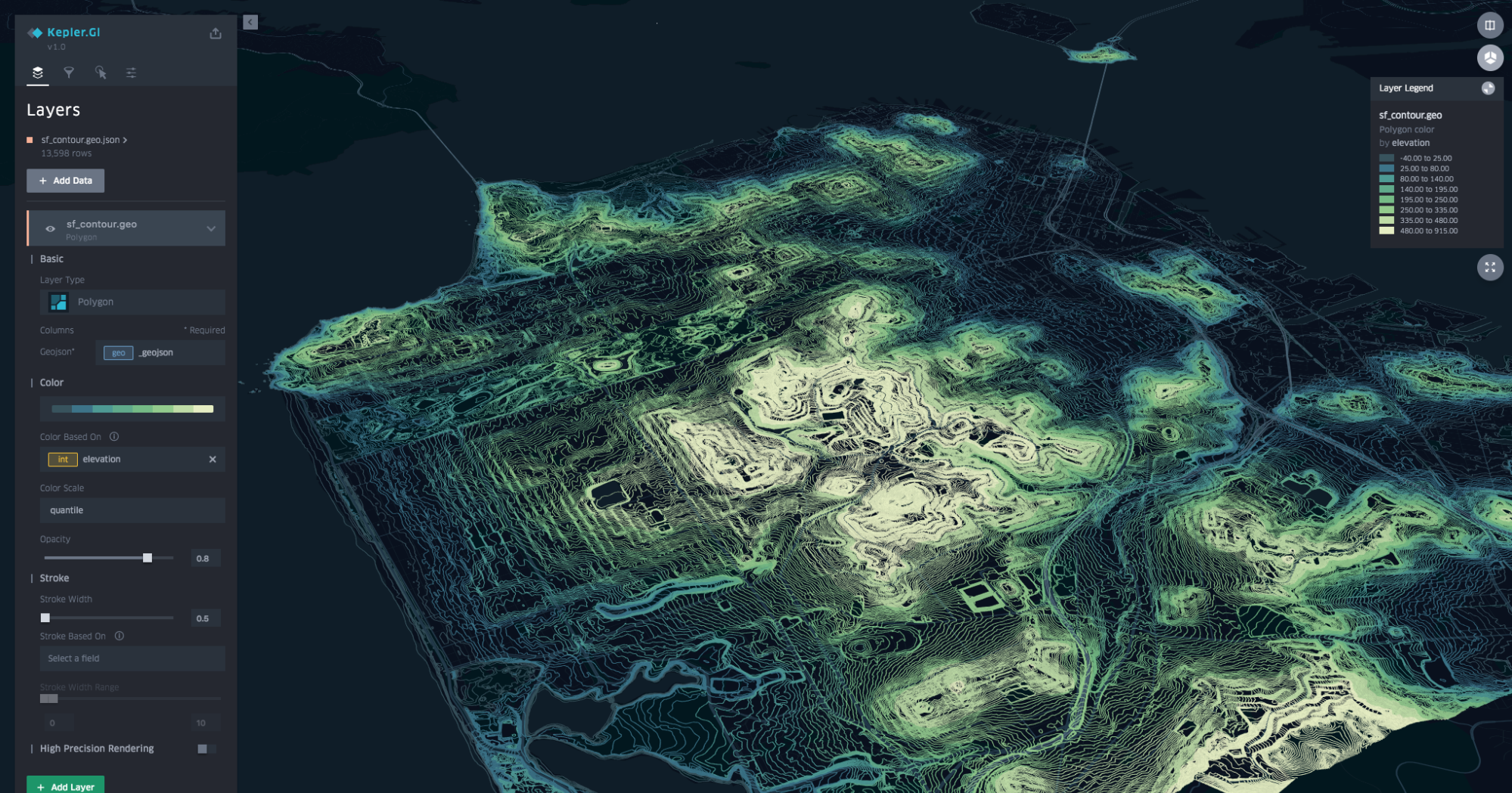
Introducing kepler.gl, Uber’s Open Source Geospatial Toolbox
Created by Uber’s Visualization team, kepler.gl is an open source data agnostic, high-performance web-based application for large-scale geospatial visualizations. At Uber, we leverage data visualization to better understand how our cities move. Our solutions enable us to embed maps with rich location data, render millions of GPS points in the blink of an eye, and, most importantly, derive insights from them.
Read More
Reconciling GraphQL and Thrift at Airbnb
For several years, we had a few eager advocates for GraphQL at Airbnb, but the project never quite made it through the gates largely due to the perception that “GraphQL the Religion”—a worldview where all data is a graph all the way down—would be incompatible with our particular services-oriented architecture (SOA) strategy, which defines service-to-service communication using Thrift Interface Definition Language (IDL) and delivers data to clients via dedicated Presentation Services. We recently reframed a case for “GraphQL the API Layer.” Embracing how GraphQL could complement rather than compete with our Presentation Services, it found much more traction.
Read More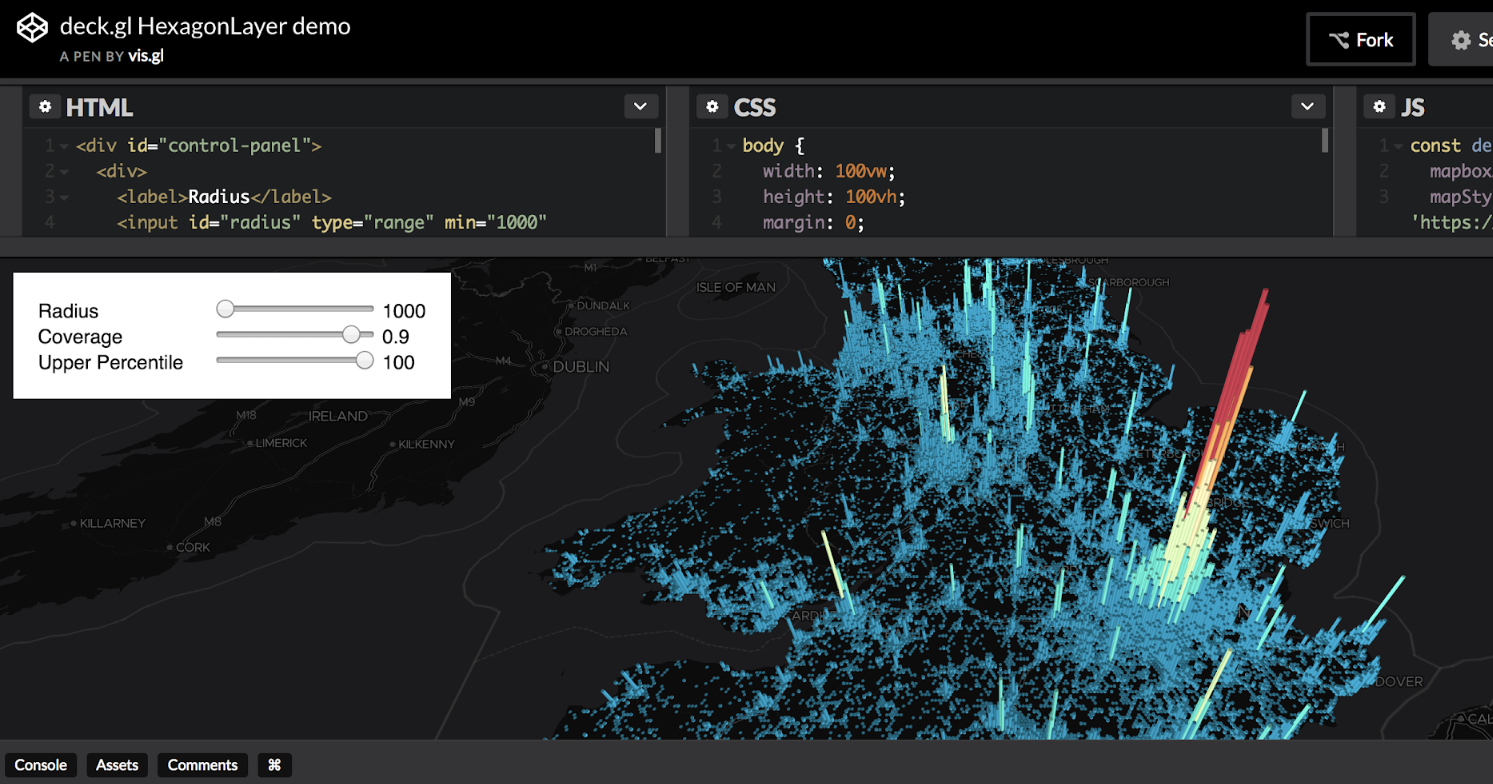
Growing the Data Visualization Community with deck.gl v5
Today, the Uber Visualization team open sourced deck.gl 5.3, the final deck.gl v5 release of our data visualization software. The v5 releases represent a major effort devoted to making deck.gl easier to use than ever before, and we hope that by sharing the story behind these improvements, we can get users excited to try out deck.gl v5’s new simplified APIs and features. While a lot of code required modification, the most important part of making deck.gl independent from React was deciding how the new non-React-based API should look.
Read More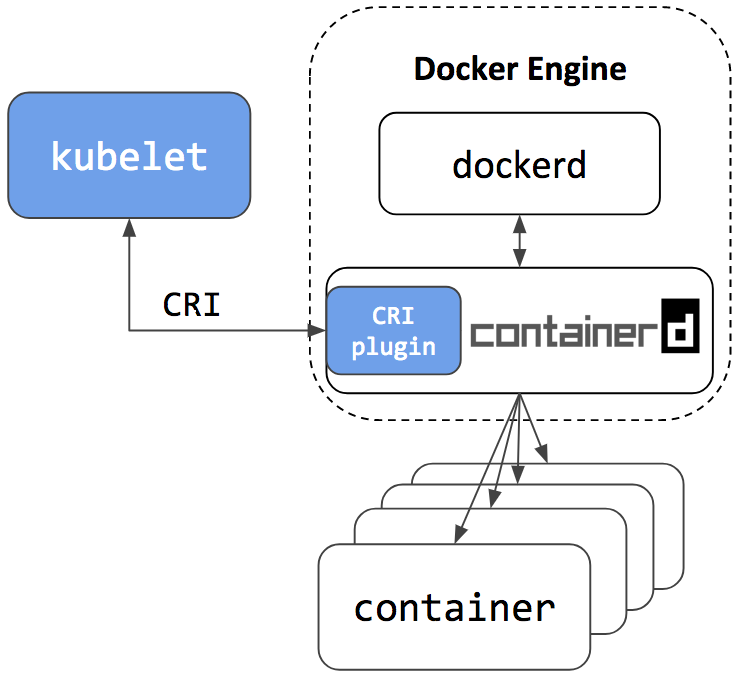
Kubernetes Containerd Integration Goes GA
Containerd 1.1 works with Kubernetes 1.10 and above, and supports all Kubernetes features. The test coverage of containerd integration on Google Cloud Platform in Kubernetes test infrastructure is now equivalent to the Docker integration (See: test dashboard). We’re very glad to see containerd rapidly grow to this big milestone.
Read More
Showdown: MySQL 8 vs. PostgreSQL 10
Now that MySQL 8 and PostgreSQL 10 are out, it’s a good time to revisit how the two major open source relational databases compete against each other. Before these versions, the general perception has been that while Postgres is superior in feature sets and its pedigree, MySQL is more battle tested at scale with massive concurrent reads/writes. But with the latest releases, the gap between the two has gotten significantly narrowed.
Read More
Open-sourcing gVisor, a sandboxed container runtime
Containers have revolutionized how we develop, package, and deploy applications. However, the system surface exposed to containers is broad enough that many security experts don’t recommend them for running untrusted or potentially malicious applications. A growing desire to run more heterogenous and less trusted workloads has created a new interest in sandboxed containers—containers that help provide a secure isolation boundary between the host OS and the application running inside the container.
Read More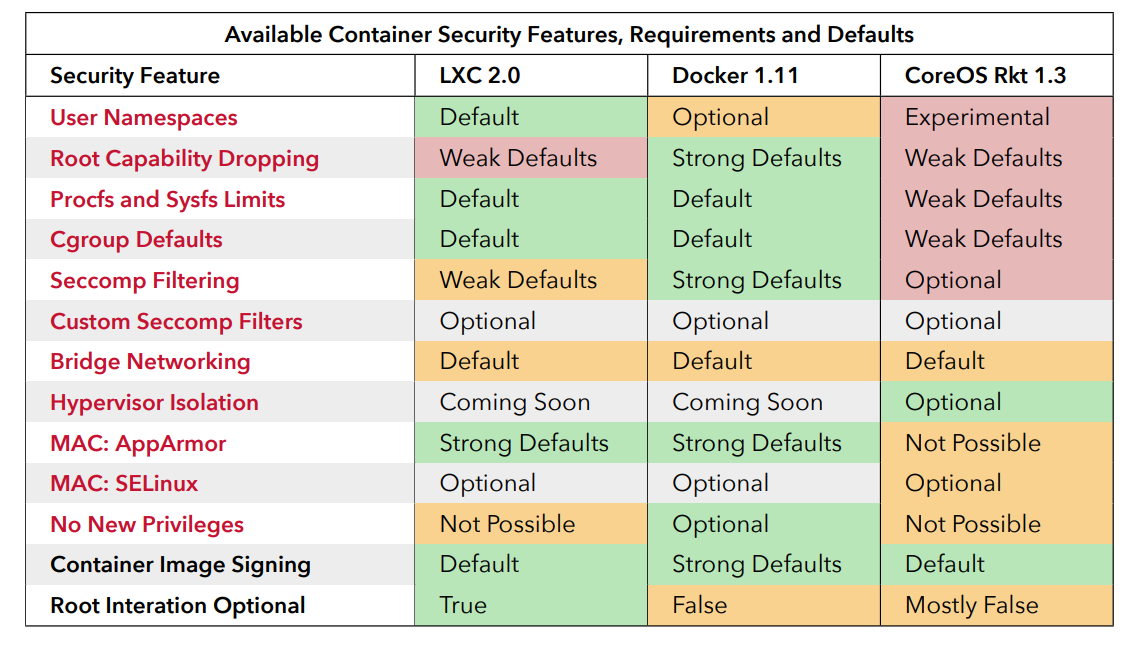
Containers, Security and Echo chambers
There seems to be some confusion around sandboxing containers as of late, mostly because of the recent launch of gvisor. Before I get into the body of this post I would like to make one thing clear. I have no problem with gvisor itself.
Read More
Introducing Git protocol version 2
Today we announce Git protocol version 2, a major update of Git’s wire protocol (how clones, fetches and pushes are communicated between clients and servers). This update removes one of the most inefficient parts of the Git protocol and fixes an extensibility bottleneck, unblocking the path to more wire protocol improvements in the future. The main motivation for the new protocol was to enable server side filtering of references (branches and tags).
Read More
Introducing Thanos: Prometheus at Scale
Prometheus’s simple and reliable operational model is one of its major selling points. However, past a certain scale, we’ve identified a few shortcomings. To resolve those, we’re today officially announcing Thanos, an open source project by Improbable to seamlessly transform existing Prometheus deployments in clusters around the world into a unified monitoring system with unbounded historical data storage.
Read More
Gardener: Manage Kubernetes clusters across multiple cloud providers
Many Open Source tools exist which help in creating and updating single Kubernetes clusters. However, the more clusters you need the harder it becomes to operate, monitor, manage and keep all of them alive and up-to-date. And that is exactly what project Gardener focuses on.
Read More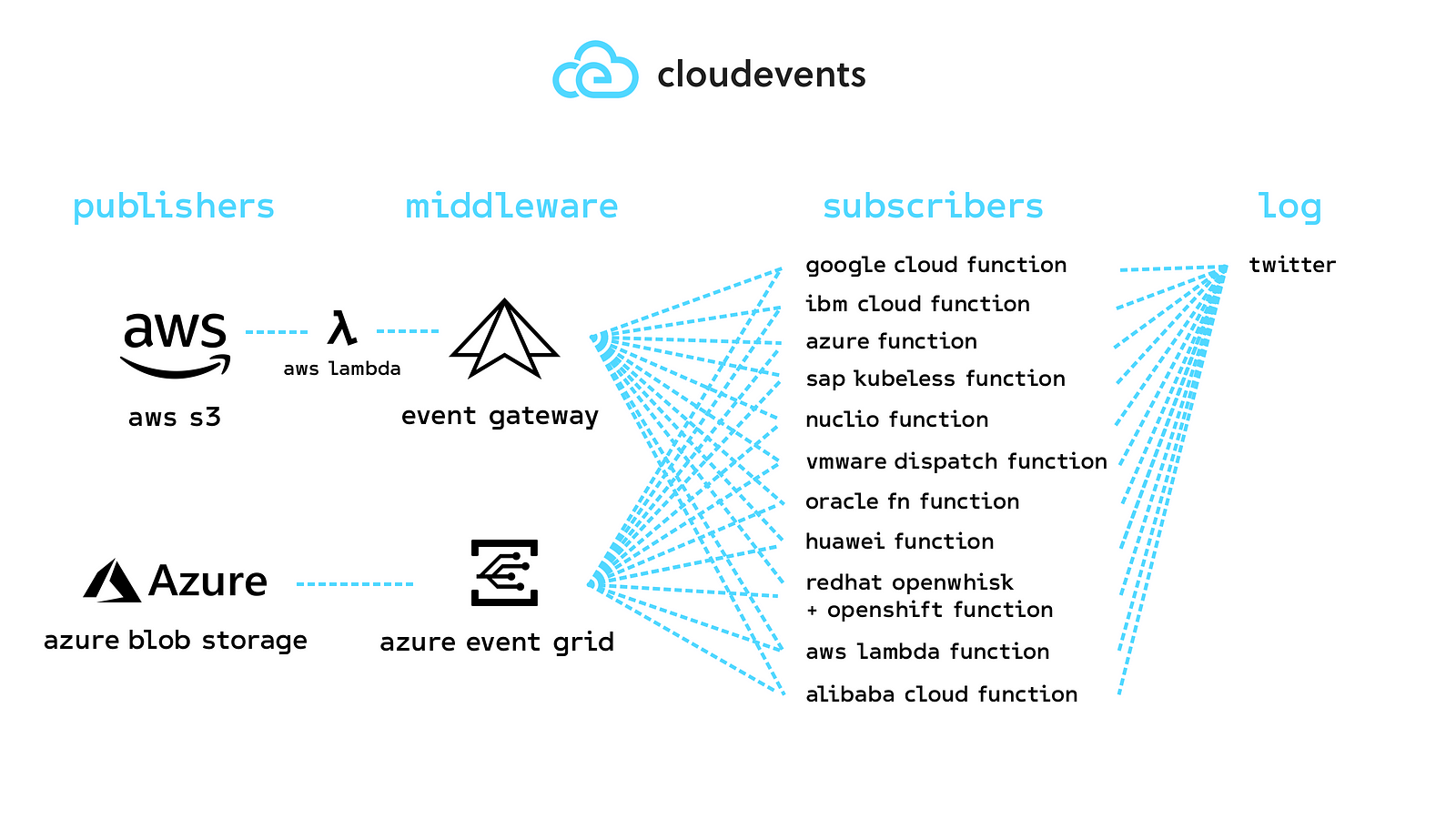




Things I’ve learned using serverless
After the tour-de-force of Serverlessconf in October, I decided my entire company would be going serverless. I spent the first couple of months beating my head against the wall trying to migrate a Python Flask app to Lambda—these efforts helped me find a better way.
Read More
Performance analysis of cloud applications
Today’s choice gives us an insight into how Google measure and analyse the performance of large user-facing services such as Gmail (from which most of the data in the paper is taken). It’s a paper in two halves. The first part of the paper demonstrates through an analysis of traffic and load patterns why the only real way to analyse production performance is using live production systems.
Read More
Sapienz: Intelligent automated software testing at scale
Shipping code updates to the Facebook app, which is used every day by hundreds of millions of people, requires extensive testing to ensure stability and performance. At Facebook’s scale, this process requires checking hundreds of important interactions across numerous types of devices and operating systems for both correctness and speed. Traditionally, this has largely been a manual test design process, during which engineers devote time and resources to designing test cases.
Read More

Linux System Monitoring with eBPF
The Linux kernel is an abundant component of modern IT systems. It provides the critical services of hardware abstraction and time-sharing to applications. The classical metrics for monitoring Linux are among the most well known metrics in monitoring: CPU utilization, memory usage, disk utilization, and network throughput.
Read More
Altair: Declarative Visualization in Python
With Altair, you can spend more time understanding your data and its meaning. Altair’s API is simple, friendly and consistent and built on top of the powerful Vega-Lite visualization grammar. This elegant simplicity produces beautiful and effective visualizations with a minimal amount of code.
Read More
Google gVisor, a sandboxed container runtime
To that end, we’d like to introduce gVisor, a new kind of sandbox that helps provide secure isolation for containers, while being more lightweight than a virtual machine (VM). gVisor integrates with Docker and Kubernetes, making it simple and easy to run sandboxed containers in production environments.
Read More
CoreOS Introduces the Operator Framework: Building Apps on Kubernetes
You may be familiar with Operators from the concept’s introduction in 2016. An Operator is a method of packaging, deploying and managing a Kubernetes application. A Kubernetes application is an application that is both deployed on Kubernetes and managed using the Kubernetes APIs and kubectl tooling.
Read More
NetChain: Scale-free sub-RTT coordination
NetChain won a best paper award at NSDI 2018 earlier this month. By thinking outside of the box (in this case, the box is the chassis containing the server), Jin et al. have demonstrated how to build a coordination service (think Apache ZooKeeper) with incredibly low latency and high throughput.
Read More

Lessons from Building Static Analysis Tools at Google
Here, we describe how we have applied the lessons from Google’s previous experience with FindBugs Java analysis, as well as from the academic literature, to build a successful static analysis infrastructure used daily by most software engineers at Google. Google’s tooling detects thousands of problems per day that are fixed by engineers, by their own choice, before the problematic code is checked into Google’s companywide codebase.
Read More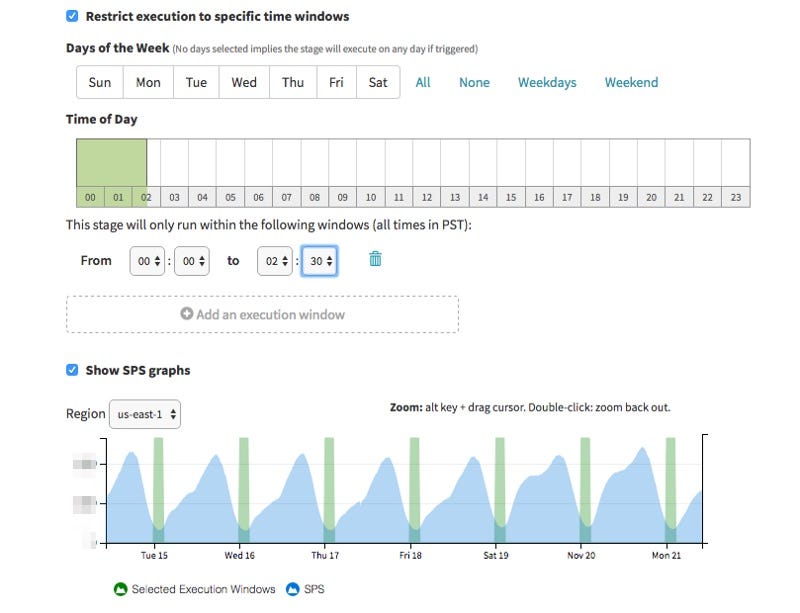
Tips for High Availability
Over the past four years, Netflix has gone from less than 50 Million subscribers to 125 Million subscribers. While this kind of growth has caused us no shortage of scaling challenges, we actually managed to improve the overall availability of our service in that time frame. Along the way, we have learned a lot and now have a much better understanding of what it takes to make our system more highly available.
Read More
Notes on structured concurrency, or: Go statement considered harmful
In this post, I want to convince you that nurseries aren’t quirky or idiosyncratic at all, but rather a new control flow primitive that’s just as fundamental as for loops or function calls. And furthermore, the other approaches we saw above – thread spawning and callback registration – should be removed entirely and replaced with nurseries.
Read More
Caddy – The HTTP/2 Web Server with Automatic HTTPS
All you have to do is run caddy and voilà! Caddy automatically loads your Caddyfile if it’s in the same folder. For production sites, HTTPS is on by default!
Read More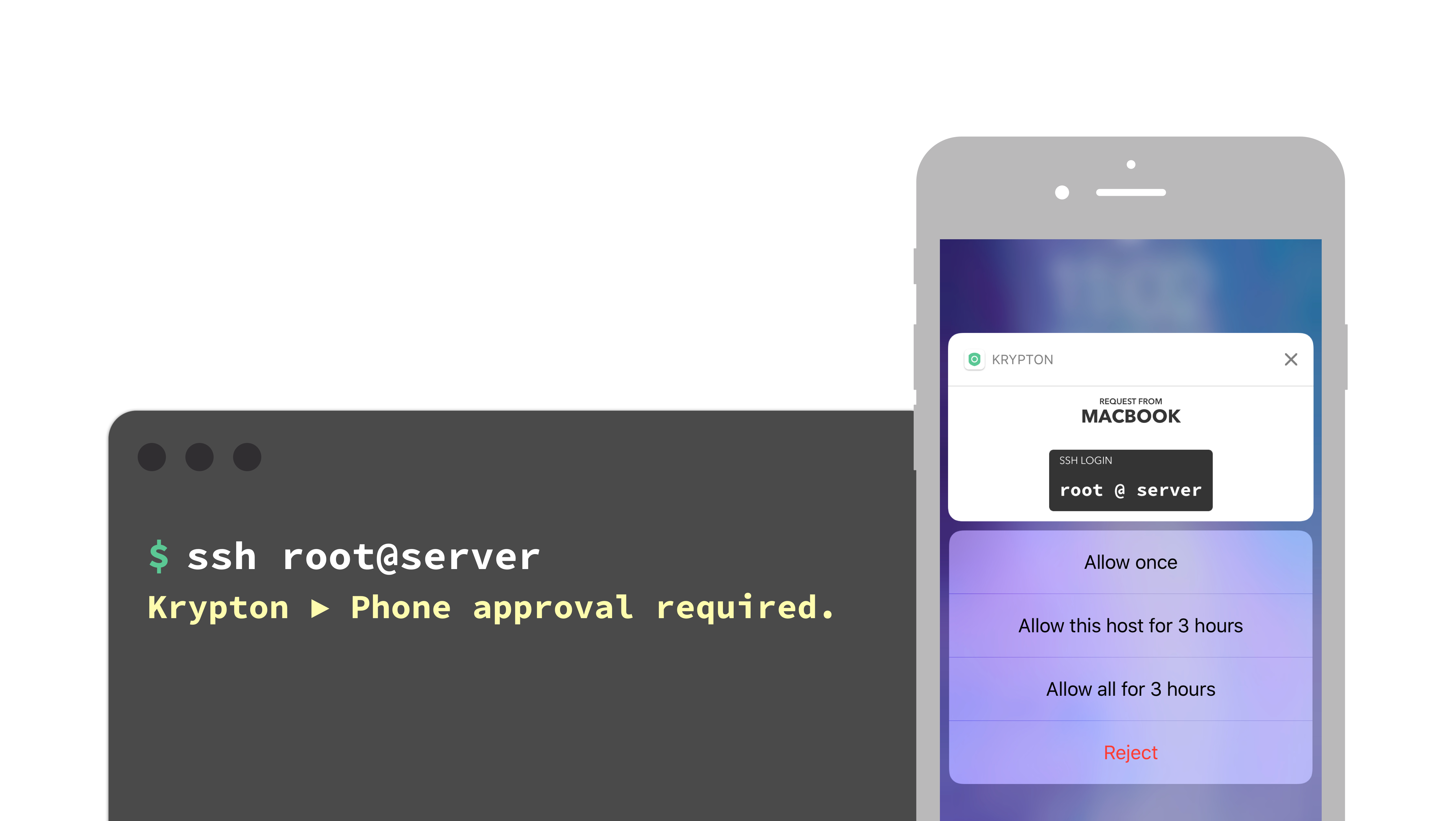


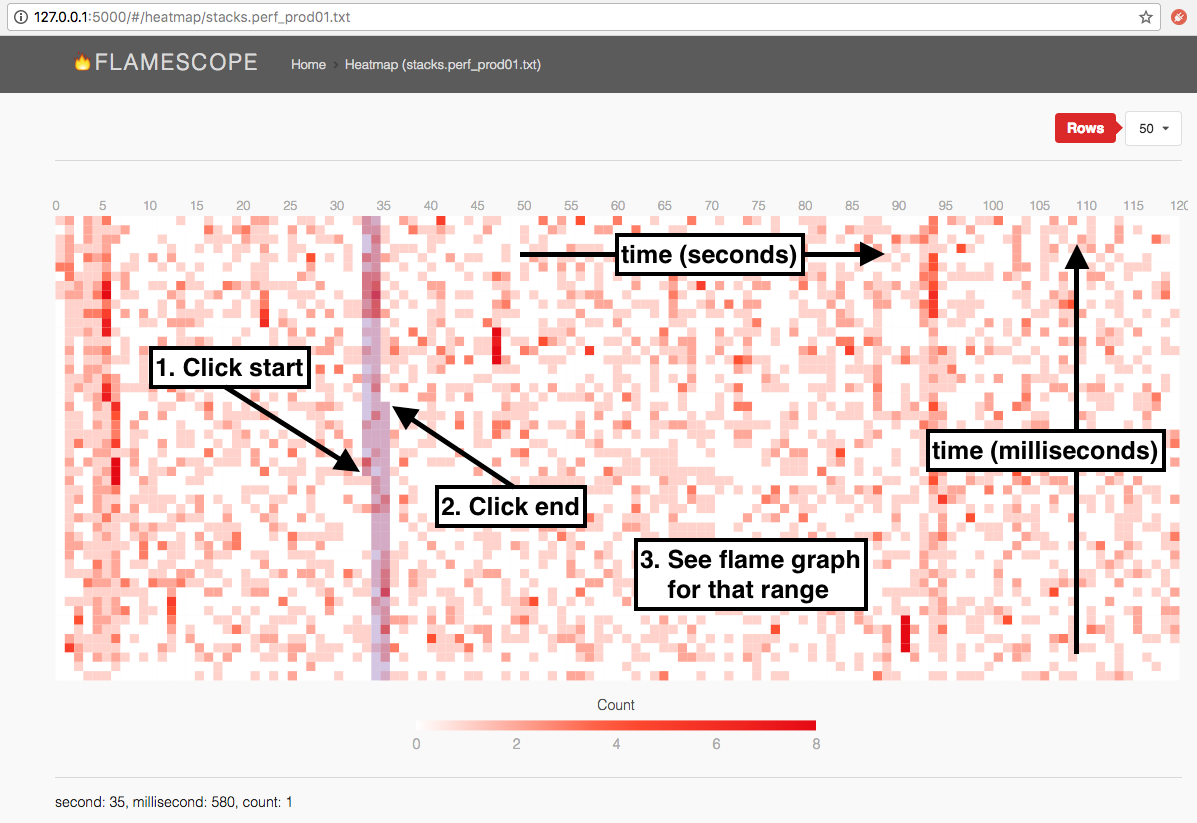
Netflix FlameScope
We’re excited to release FlameScope: a new performance visualization tool for analyzing variance, perturbations, single-threaded execution, application startup, and other time-based issues. It has been created by the Netflix cloud performance engineering team and just released as open source, and we welcome help from others to develop the project further. (If it especially interests you, you might be interested in joining Netflix to work on it and other projects.)
Read More
Fluree DB – A scalable blockchain database
Develop blockchain applications with a powerful graph database. FlureeDB’s blockchain database allows developers to build decentralized applications on blockchain technology. Support for GraphQL, JavaScript, and React built in.
Read More

GraalVM: Run Programs Faster Anywhere
Zero overhead interoperability between programming languages allows you to write polyglot applications and select the best language for your task.
Read More
EdgeDB: A new open-source object relational database
Databases have always been and will always be the defining piece of any technological stack. In the last decade there has been a lot of activity and interesting developments in the field. Just 10 years ago there was no MongoDB, no affordable cloud databases, and even cloud itself was a relatively new concept.
Read More

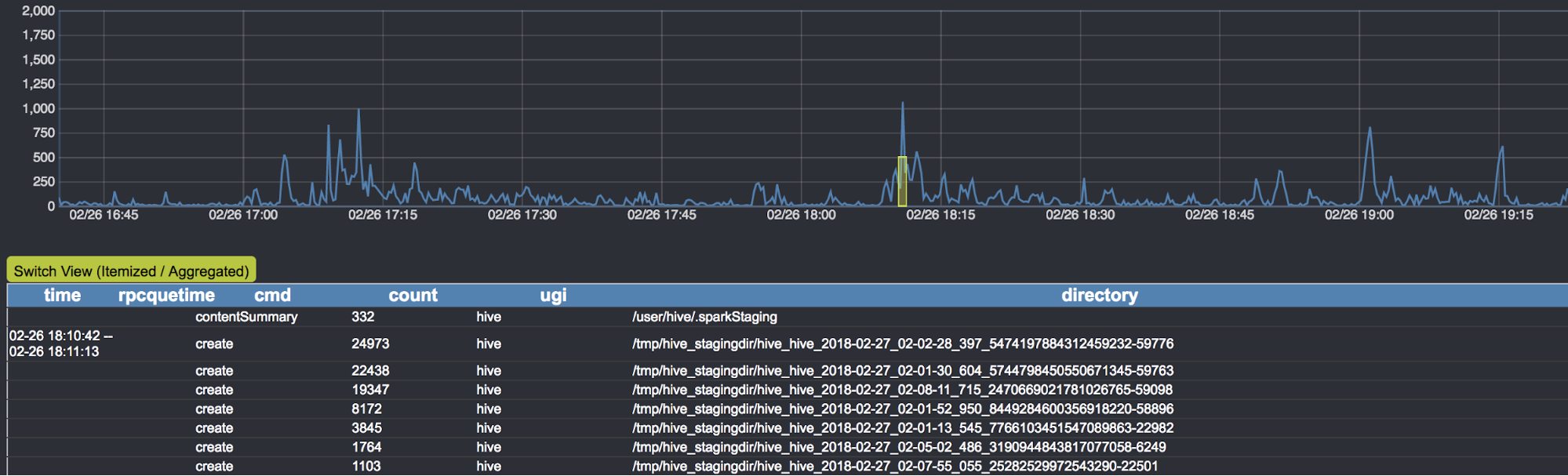
Scaling Uber’s Hadoop Distributed File System for Growth
Uber’s Data Infrastructure team overhauled our approach to scaling our storage infrastructure by incorporating several new features and functionalities, including ViewFs, NameNode garbage collection tuning, and an HDFS load management service.
Read More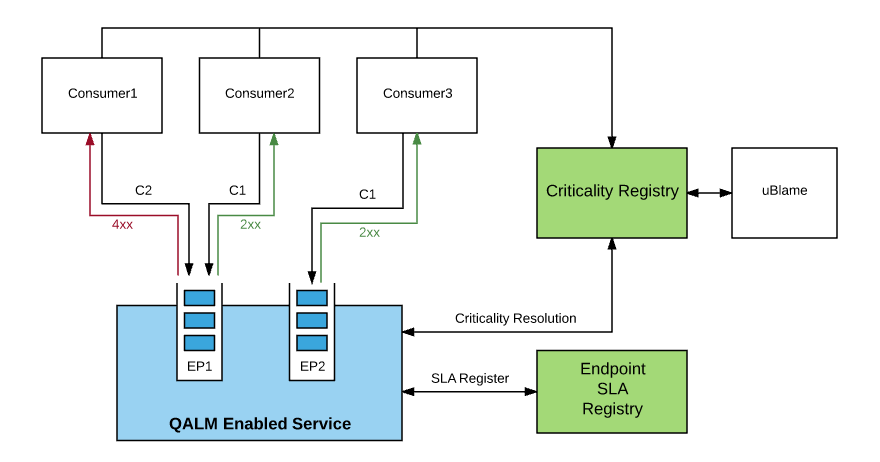
Introducing QALM, Uber’s QoS Load Management Framework
To proactively manage our traffic loads based on the criticality of requests, we built QoS Aware Load Management (QALM), a dynamic load shedding framework for incoming requests based on criticality. When the service degrades due to traffic overload, resource exhaustion, or dependency failure, QALM prioritizes server resources for more critical requests and sheds less critical ones. Our goal with QALM is to reduce the frequency and severity of any outages or incidents, leading to more reliable user experiences across our business.
Read More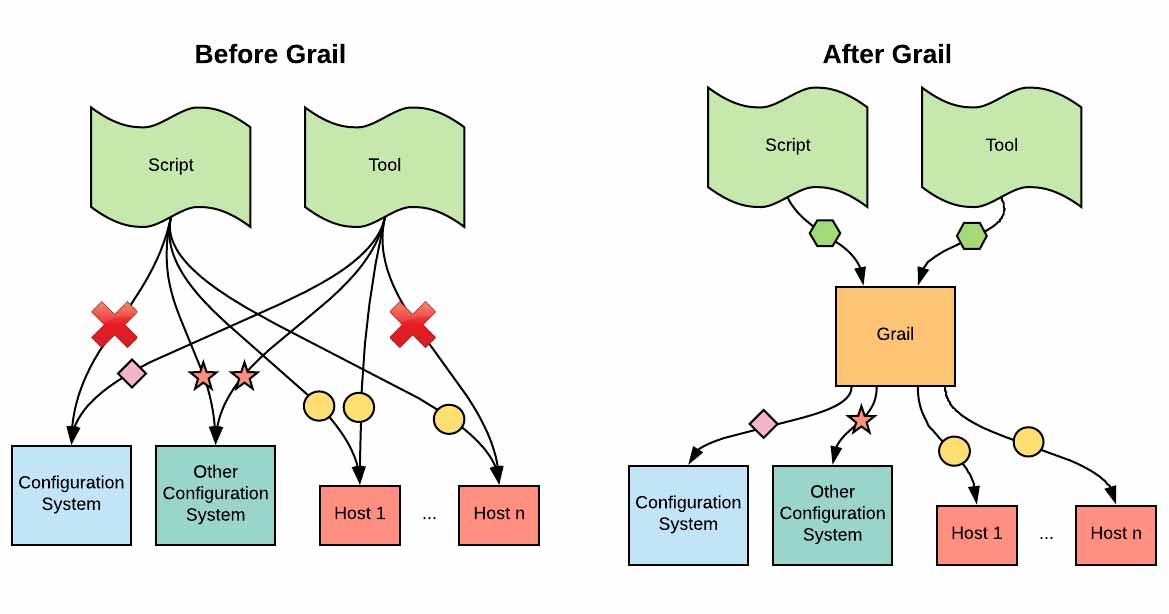
Scaling Infrastructure Management with Grail
To build and maintain infrastructure at scale, easy access to the current state of the system is paramount. As Uber’s business continues to expand, our infrastructure has grown in size and complexity, making it more difficult to get all the information we need, when we need it.
Read More