
Engineering For Failure
A set of practical patterns to recover from failures in external services Not so long ago, our systems were simple: we had one machine, with one process, probably no more than one external datastore, and the entire request lifecycle was processed and handled within this simple world. Our users were also accustomed to a certain SLA standard — a 2-second page load time could have been acceptable a few years ago, but waiting more than a second for an Instagram post is unthinkable nowadays. When systems get more complex, with strict latency requirements and a distributed infrastructure, an uninvited guest crawls up our systems — request failure.
Read More
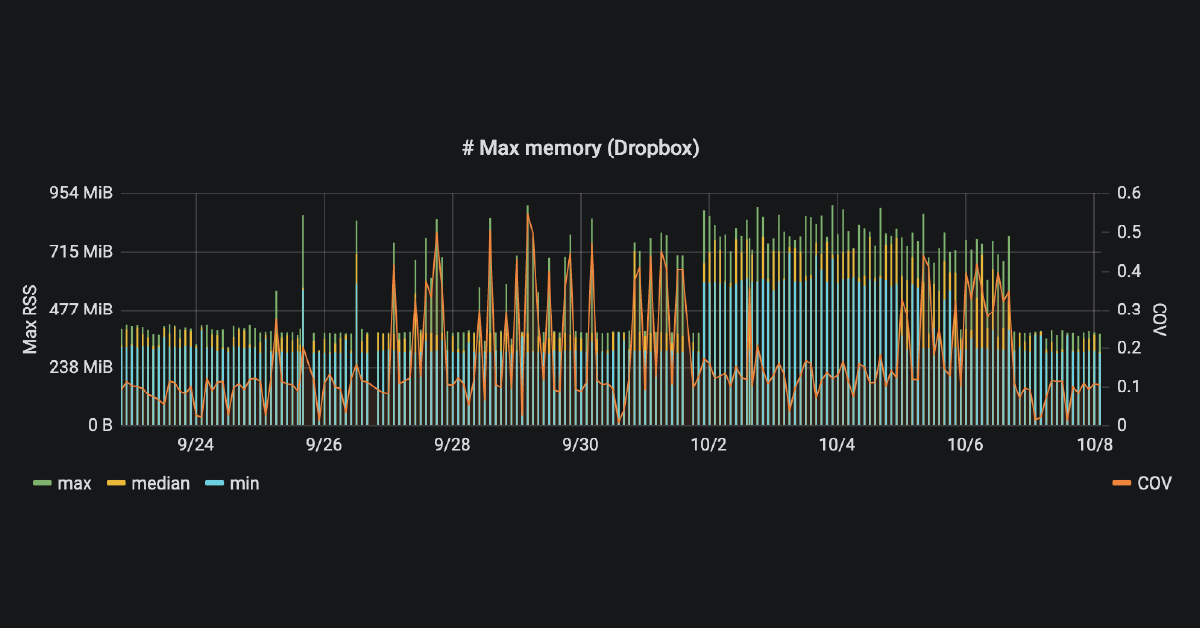
Keeping sync fast with automated performance regression detection
Sync is a hard distributed systems problem and re-writing the heart of our sync engine on the desktop client was a monumental effort. We’ve previously discussed our efforts to heavily test durability at different layers of the system. Today, we are going to talk about how we ensured the performance of our new sync engine.
Read More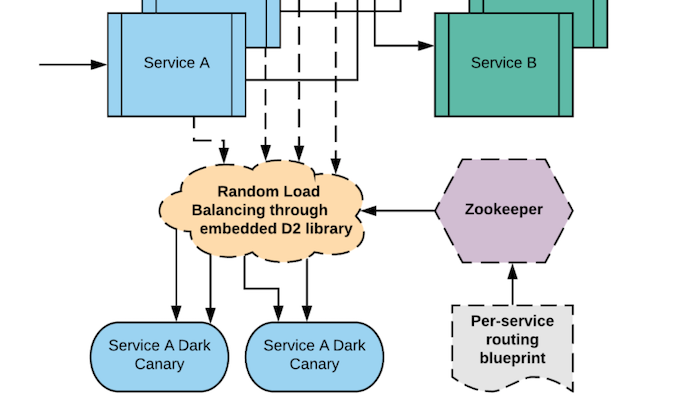
Production testing with dark canaries
Back in 2013, one of our large backend services wanted support in Rest.li for dark canaries. The service, at the time, involved duplicating requests from one host machine and sending it to another host machine. This was added via a Python tool to populate the host-to-host mapping in Apache ZooKeeper along with a filter to read this mapping and multiply traffic.
Read More
Building storage-first serverless applications with HTTP APIs service integrations
Over the last year, I have been talking about “storage first” serverless patterns. With these patterns, data is stored persistently before any business logic is applied. The advantage of this pattern is increased application resiliency.
Read More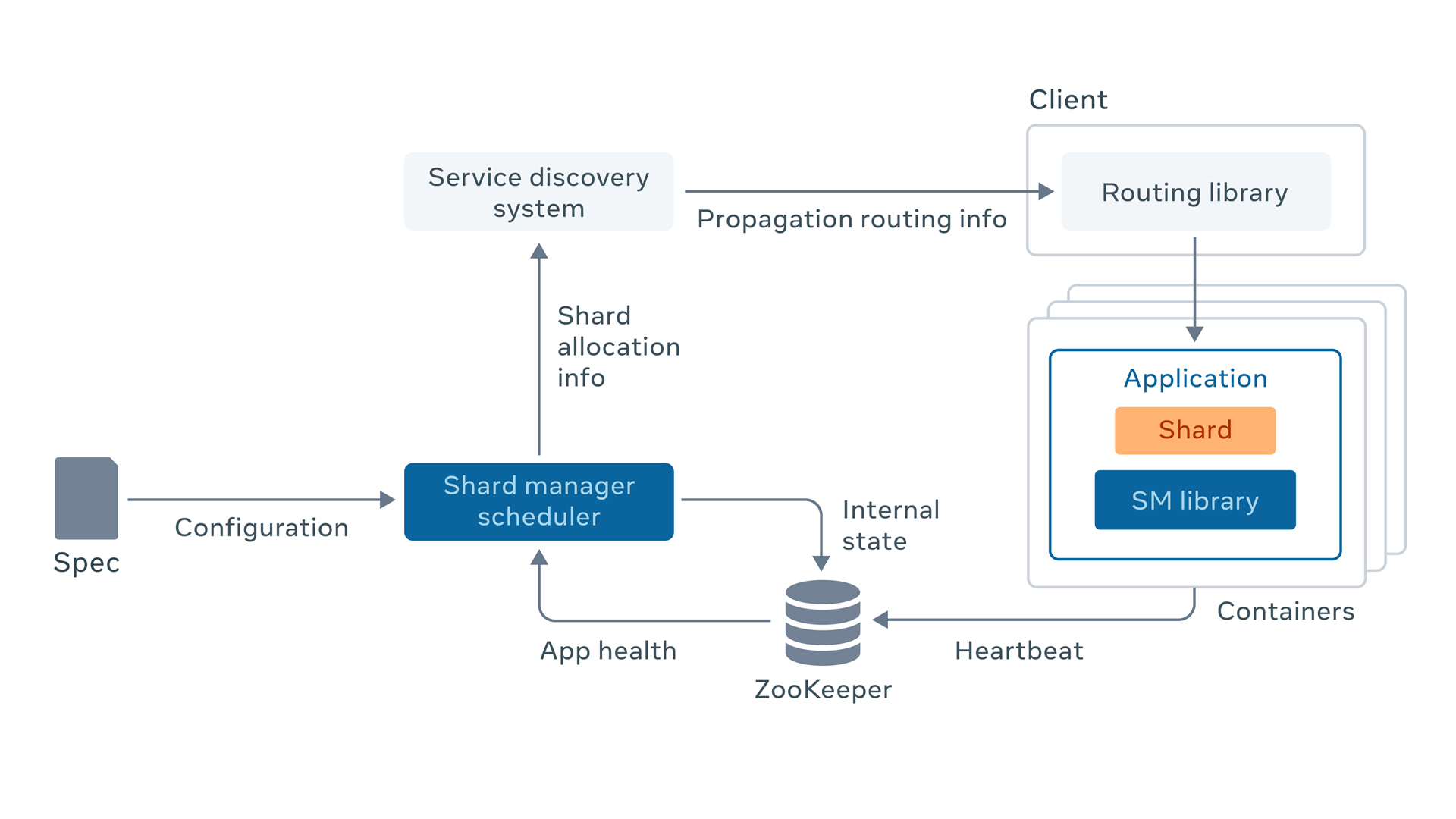
Scaling services with Shard Manager
We look at how Shard Manager is fully integrated in Facebook’s infrastructure ecosystem and provides a holistic, end-to-end solution supporting basic shard failover as well as sophisticated load balancing, shard scaling, and operational safety. Over the years, as we’ve expanded in scale and functionalities, Facebook has evolved from a basic web server architecture into a complex one with thousands of services working behind the scenes. It’s no trivial task to scale the wide range of back-end services needed for Facebook’s products.
Read More3 Years of Kubernetes in Production–Here’s What We Learned
We started out building our first Kubernetes cluster in 2017, version 1.9.4. We had two clusters, one that ran on bare-metal RHEL VMs, and another that ran on AWS EC2. Today, our Kubernetes infrastructure fleet consists of over 400 virtual machines spread across multiple data-centres.
Read More
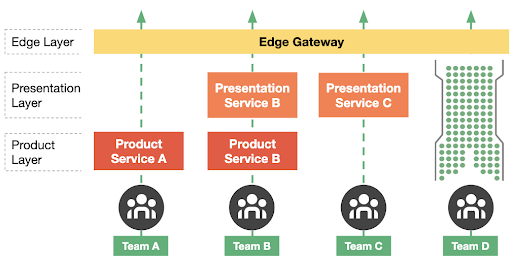
Designing Edge Gateway, Uber’s API Lifecycle Management Platform
In October 2014, Uber had started its journey of scale in what would eventually turn out to be one of the most impressive growth phases in the company. Over time we were scaling our engineering teams non-linearly each month and acquiring millions of users across the world. In this article, we will go through the different phases of the evolution of Uber’s API gateway that powers Uber products.
Read More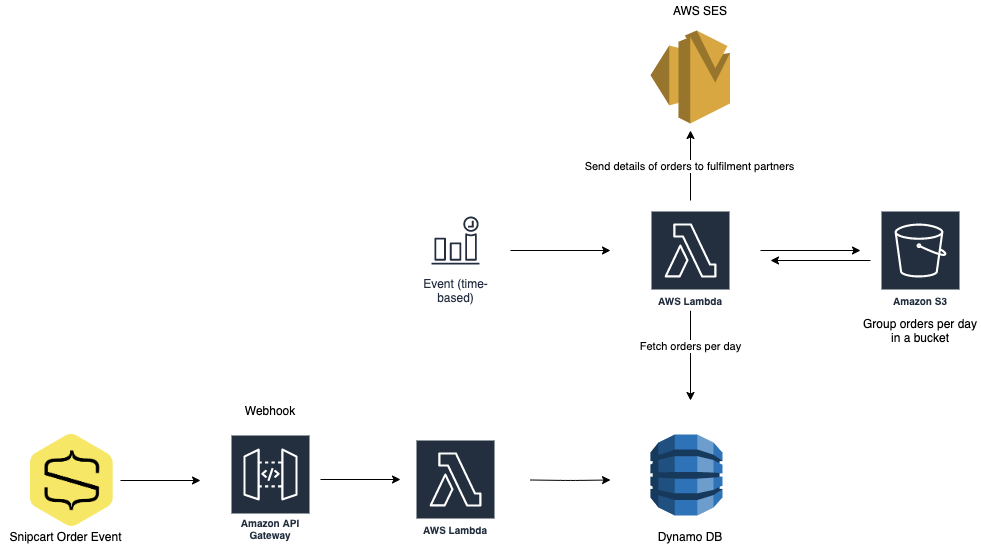


How we upgraded PostgreSQL at GitLab.com
We explain the precise maintenance process to execute a major version upgrade of PostgreSQL. The biggest challenge was to do a complete fleet major upgrade through an orchestrated pg_upgrade. We needed to have a rollback plan to optimize our capacity right after Recovery Time Objective (RTO) while maintaining a 12-node clusterâs 6TB-data consistent serving 300.000 aggregated transactions per second from around six million users.
Read MoreThree Basecamp outages. One week. What happened?
Basecamp has suffered through three serious outages in the last week, on Friday, August 28th, on Tuesday, September 1, and again today. It’s embarrassing, and we’re deeply sorry. This is more than a blip or two.
Read More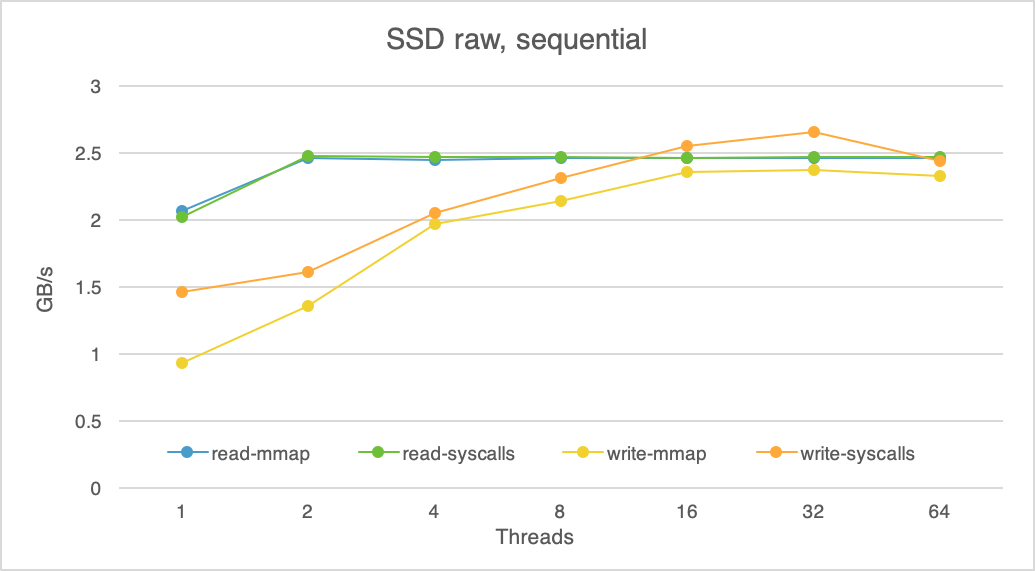
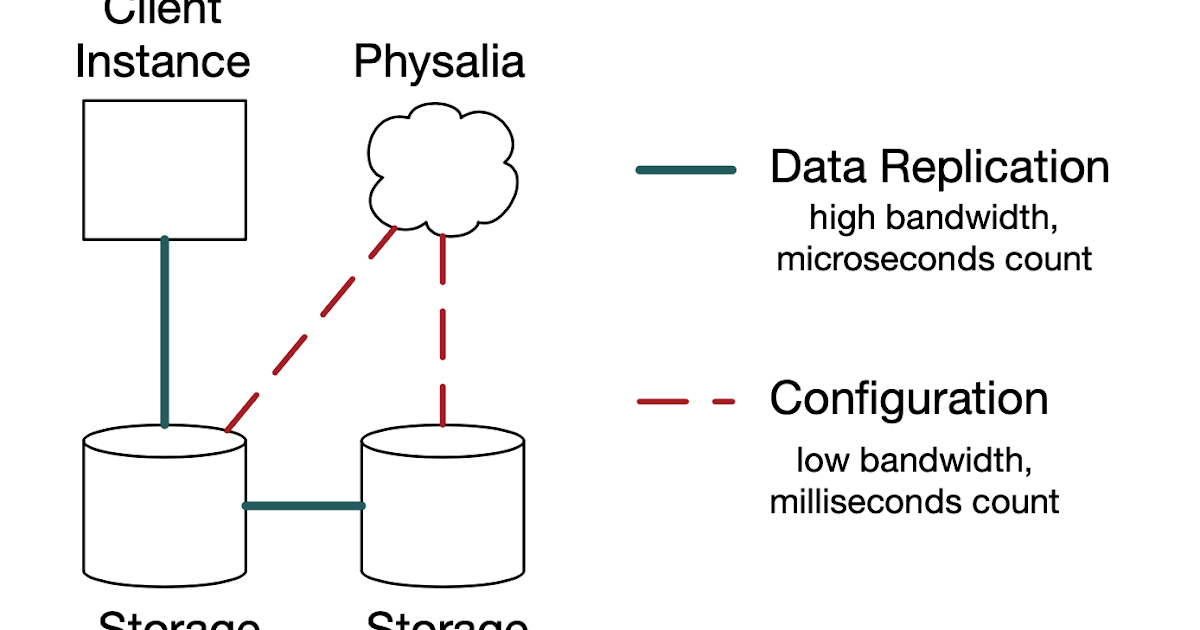
Millions of tiny databases
The Physalia configuration store for chain replication of EBS is implemented as key-value stores maintained over a large number of these cells. They built a test harness, called SimWorld, which abstracts networking, performance, and other systems concepts. The goal of this approach is to allow developers to write distributed systems tests, including tests that simulate packet loss, server failures, corruption, and other failure cases, as unit tests in the same language as the system itself.
Read More

Reducing UDP latency
Hi! I’m one of Embox RTOS developers, and in this article I’ll tell you about one of the typical problems in the world of embedded systems and how we were solving it. Control and responsibility is a key point for a wide range of embedded systems.
Read More
Cloudflare’s Current Expansion Is Different from the Others
The company is expanding its US network in a big way, and it’s turned to two edge data center startups for help. In January, Cloudflare, which helps companies make their web services run faster and be more secure – and which more recently started to use its global data center network to also provide cloud computing services – said it would expand the network in the US with three dozen new locations. Shortly thereafter, the company said it would add even more locations in the US – about the same amount as in the first announcement.
Read More
A Deep Dive into PostGIS Nearest Neighbor Search
In this post, we’re going to take a deeper dive into the Postgres and PostGIS internals to find out how this actually works. By the time we surface you will have a better understanding of the advanced technical capabilities and unparalleled extensibility of Postgres. You’ll also appreciate how the open philosophy of Postgres has fostered a development community whose collaboration over many years has provided powerful features that benefit numerous users.
Read More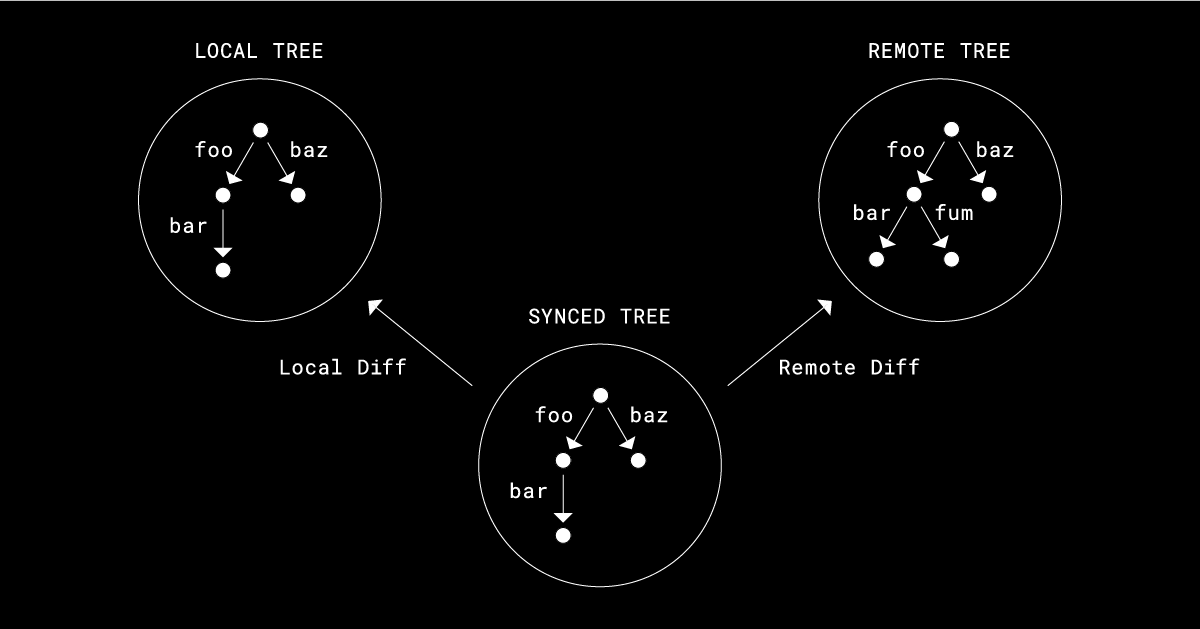
Testing sync at Dropbox
Executing a full rewrite of the Dropbox sync engine was pretty daunting. (Read more about our goals and how we made the decision in our previous post here.) Doing so meant taking the engine that powers Dropbox on hundreds of millions of user’s machines and swapping it out mid-flight.
Read More
Scaling Driver Compliance across Lyft
A passenger opens the app, requests a ride, and just a few minutes later there is a car with a friendly driver in front of them. They may know this driver went through a background check and other vetting; however, many might not realize all the complexity in the on-boarding process. Driver and vehicle requirements vary substantially across markets (and even at very proximate locations) due to varying market dynamics and government regulations.
Read More
Taming ElastiCache with Auto-discovery at Scale
Our backend infrastructure at Tinder relies on Redis-based caching to fulfill the requests generated by more than 2 billion uses of the Swipe® feature per day and hosts more than 30 billion matches to 190 countries globally. Most of our data operations are reads, which motivates the general data flow architecture of our backend microservices.
Read More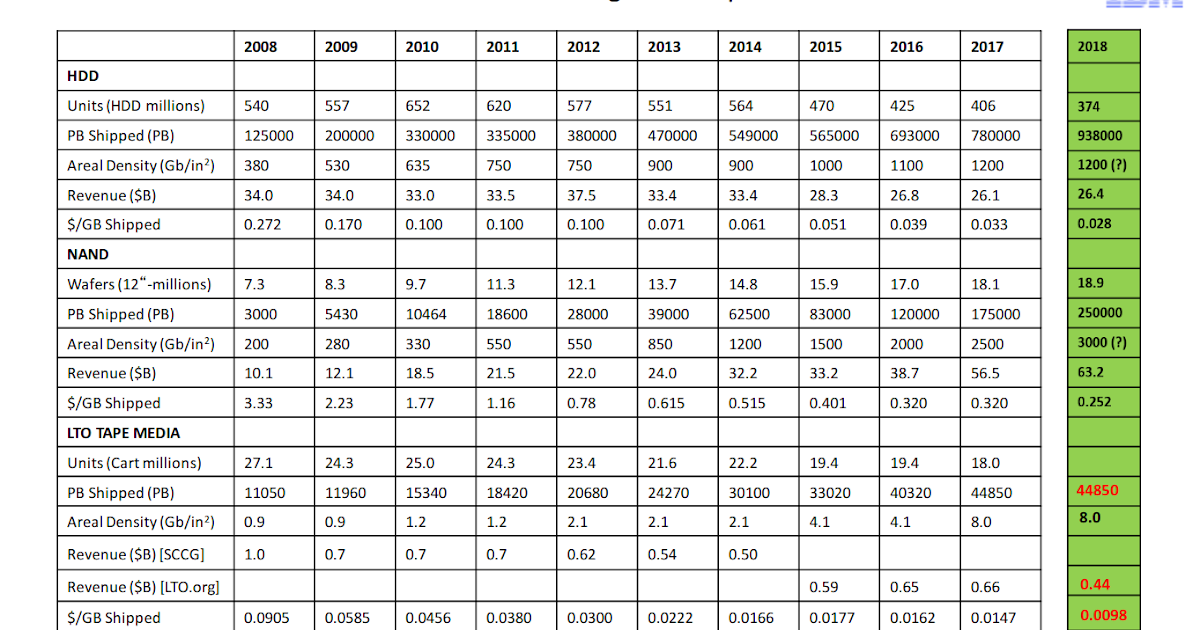
Library of Congress Storage Architecture
In 2026 is there demand for 7X more manufactured storage annually and is there sufficient value for this storage to spend $122B more annually (2.4X) for this storage? Unlike HDD, tape magnetic physics is not the limiting issues since tape bit cells are 60X larger than HDD bit cells … The projected tape areal density in 2025 (90 Gbit/in2) is 13x smaller than today’s HDD areal density and has already been demonstrated in laboratory environments.
Read More
How we 30x’d our Node parallelism
What’s the best way to safely increase parallelism in a production Node service? That’s a question my team needed to answer a couple of months ago. We were running 4,000 Node containers (or ‘workers’) for our bank integration service.
Read More
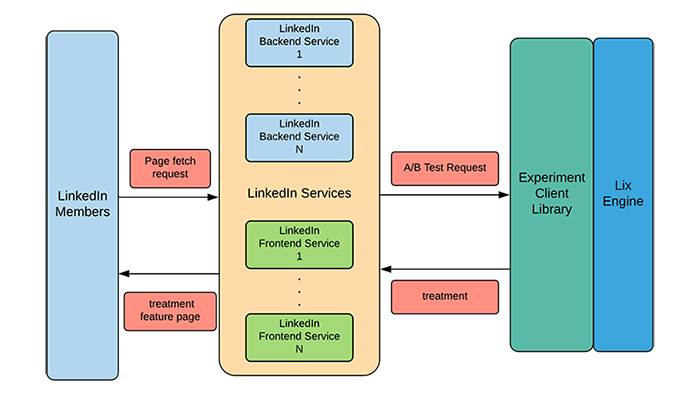
Making the LinkedIn experimentation engine 20x faster
At LinkedIn, we like to say that experimentation is in our blood because no production release at the company happens without experimentation; by “experimentation,” we typically mean “A/B testing.” The company relies on employees to make decisions by analyzing data. Experimentation is a data-driven foundation of the decision-making process, which helps with measuring the precise impact of every change and release, and evaluating whether expectations meet reality.
Read More
Lyft’s Journey through Mobile Networking
In 5 years, the number of endpoints consumed by Lyft’s mobile apps grew to over 500, and the size of our mobile engineering team increased by more than 15x. To scale with this growth, our infrastructure had to evolve dramatically to utilize new advances in modern networking in order to continue to provide benefits for our users. This post describes the journey through the evolution of Lyft’s mobile networking: how it’s changed, what we’ve learned, and why it’s important for us as a growing business.
Read More
Database Migration To Amazon Aurora
In this blog post we’ll show you how we migrated a critical Postgres database with 18Tb of data from Amazon RDS (Relational Database Service) to Amazon Aurora, with minimal downtime. To do so, we’ll discuss our experience at Codacy.
Read More
Automating Datacenter Operations at Dropbox
Switch provisioning at Dropbox is handled by a Pirlo component called the TOR Starter. The TOR Starter is responsible for validating and configuring switches in our datacenter server racks, PoP server racks, and at the different layers of our datacenter fabric that connect racks in the same facility together. Writing the TOR Starter on top of the ClusterOps queue provides us with a basic manager-worker queuing service.
Read More
Kubernetes Failure Stories
I started to compile a list of public failure/horror stories related to Kubernetes. It should make it easier for people tasked with operations to find outage reports to learn from. Since we started with Kubernetes at Zalando in 2016, we collected many internal postmortems.
Read More
The Biggest IT Failures of 2018
This year provedonce againthat IT-related failures “are universally unprejudiced: they happen in every country; to large companies and small; in commercial, nonprofit, and governmental organizations; and without regard to status or reputation.” Below is a review that just scratches the surface of the sundry failures, glitches, and other IT hiccups that made the news in 2018. This year saw a slight reduction in the number of flight cancellations and delays due to computer-related problems as compared with the past three years, especially in the United States.
Read More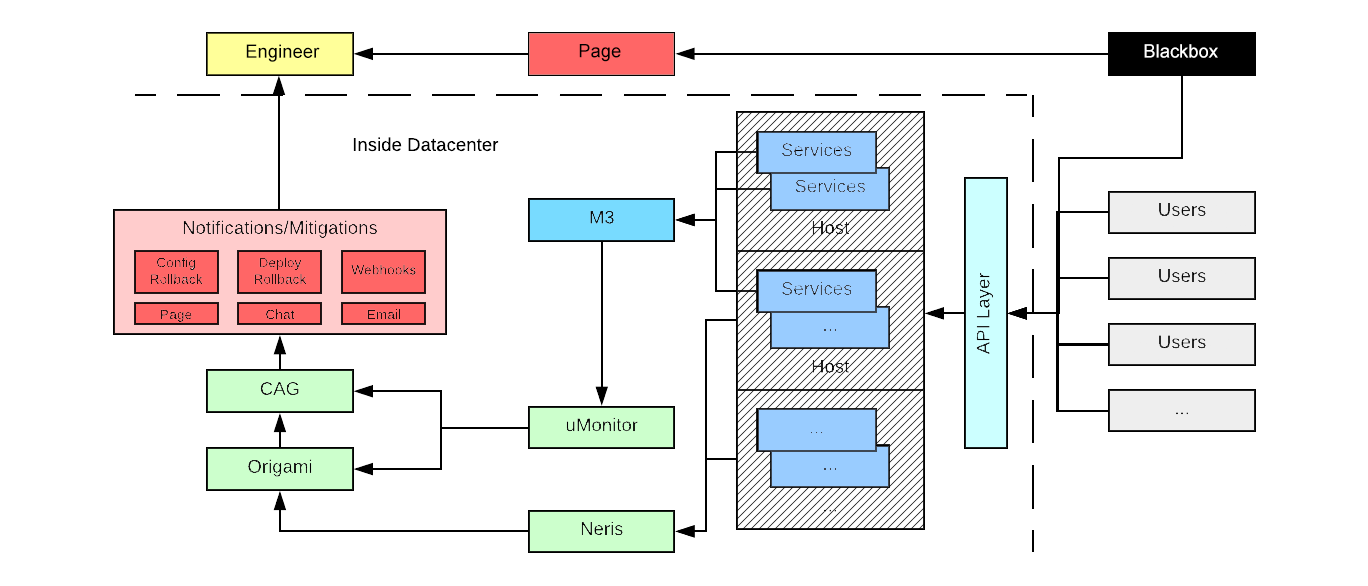
Observability at Scale: Building Uber’s Alerting Ecosystem
Uber’s software architectures consists of thousands of microservices that empower teams to iterate quickly and support our company’s global growth. These microservices support a variety of solutions, such as mobile applications, internal and infrastructure services, and products along with complex configurations that affect these products at city and sub-city levels. To maintain our growth and architecture, Uber’s Observability team built a robust, scalable metrics and alerting pipeline responsible for detecting, mitigating, and notifying engineers of issues with their services as soon as they occur.
Read More
Stack Overflow: How We Do Monitoring
What is monitoring? As far as I can tell, it means different things to different people. But we more or less agree on the concept.
Read More
Cape Technical Deep Dive
In this post, we’ll take a deep dive into the design of the Cape framework. First, we’ll discuss Cape’s architecture. Then we’ll look at the core scheduling component of the system.
Read More
Bye bye Mongo, Hello Postgres
In April the Guardian switched off the Mongo DB cluster used to store our content after completing a migration to PostgreSQL on Amazon RDS. This post covers why and how At the Guardian, the majority of content – including articles, live blogs, galleries and video content – is produced in our in-house CMS tool, Composer. This, until recently, was backed by a Mongo DB database running on AWS.
Read More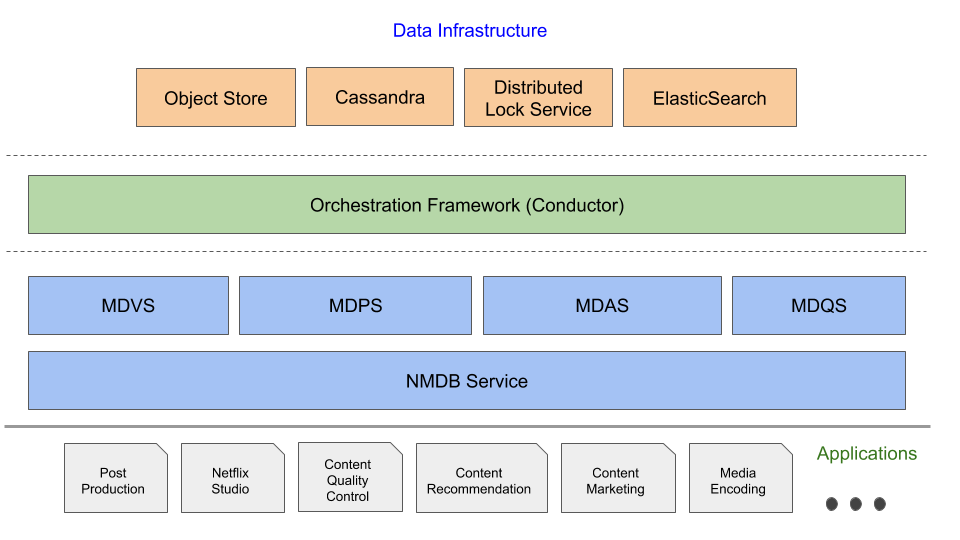
Implementing the Netflix Media Database
In the previous blog posts in this series, we introduced the Netflix Media DataBase (NMDB) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements—these will serve as the necessary motivation for the architectural choices we made. A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve.
Read More
Scaling Cash Payments in Uber Eats
This article is the fourth in a series covering how Uber’s mobile engineering team developed the newest version of our driver app, codenamed Carbon, a core component of our ridesharing business. Among other new features, the app lets our population of over three million driver-partners find fares, get directions, and track their earnings. We began designing the new app in conjunction with feedback from our driver-partners in 2017 and began rolling it out for production in September 2018.
Read More
Building Services at Airbnb Part 3
In the third post of our series on scaling service development, we dive into resilience engineering practices built into the standard service platform that powers the new Services Oriented Architecture atAirbnb. Airbnb is moving its infrastructure towards a Service Oriented Architecture. A reliable, performant, and developer-friendly polyglot service platform is an underpinning component in Airbnb’s architectural evolution.
Read More

Sessionizing Uber Trips in Real Time
Uber’s many data flows required modeling the data associated with a specific task, such as a rider trip, into a state machine. The state machine lets engineers focus on just the events needed to successfully accomplish a trip. In one sense, Uber’s challenge of efficiently matching riders and drivers in the real world comes down to the question of how to collect, store, and logically arrange data.
Read More

Large Scale NoSQL Database Migration Under Fire
The following post describes how we migrated a large NoSql database from one vendor to another in production without any downtime or data loss. The following methodology has worked for us and has been proven to be safe and simple. I am sure that there are several techniques for migrating NoSql databases, but here are some guidelines for doing so with minimal risk, while maintaining the ability to rollback at almost any point in the process.
Read More